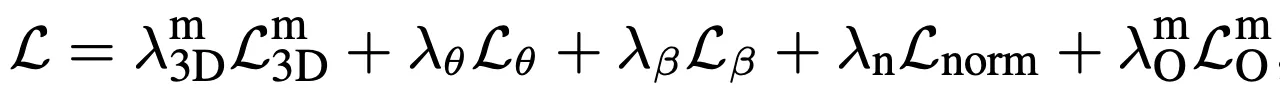introduce
다양한 human-centric video task는 동일하게 인간 관련 정보를 추정하는 것으로부터 시작되지만, 각 task마다 개별적인 방식으로 모델 연구가 진행 되었다. 그로인해 기존 연구들은 특정 task에 최적화되어 다른 데이터셋들의 장점을 차용할 수 없었다. 그러므로 본 논문에서는 다양한 human task에서 사용 가능한 통합된 human-centric 비디오 표현을 개발하는 것을 목표로 한다.
모션캡처(정확하지만 실내 데이터셋임), in-the-wild(모션캡쳐보다 부정확하지만 다양한 배경과 사람 움직임을 포함함) 등 여러 heterogeneous 데이터셋들의 knowledge를 통합하고 이를 활용하여 서로다른 downstream task를 통합된 방식으로 다룰 수 있다.
본 논문에서는 two-stage framework(pretraining, finetuning)을 제시한다.
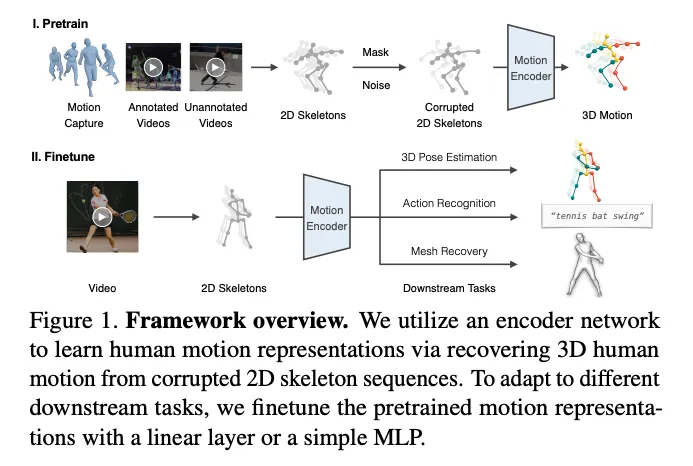
Pretraing stage
•
다양한 모션 데이터로부터 2D 키포인트 시퀀스를 추출함
•
2D 키포인트 시퀀스를 random mask와 noise를 통해 정보를 손실시킴
•
손실된 2D 키포인트 시퀀스로부터 3D 모션을 복구하도록 motion encoder를 학습시킴
•
motion encoder로 DSTformer(Dual-stream Spatio-Temporal Transformer)를 제안함으로써 키포인트 간의 long-range 관계를 포착함
Finetune stage
•
대규모, 다양한 형태의 데이터셋으로 학습한 motion representation이 서로 다른 downstream task간에 공유됨으로써 성능이 더욱 좋아진다고 가정함
•
각 task마다 그 task에 특화된 학습 데이터와 supervisory signal을 통해 pretrained motion representation을 finetune함
Contribution
Method

DSTFormer
•
N개의 모듈로 구성(dual-stream-fusion modules)
•
각 모듈은 tempral과 spatial 의 MHSA(Multi Head Self Attention)와 MLP 두 브랜치를 포함
•
Spatial MHSA: 시간 흐름에 따른 서로 다른 관절 사이의 연결을 모델링
•
Temporal MHSA: 한 관절의 움직임을 모델링
1. Network Architecture
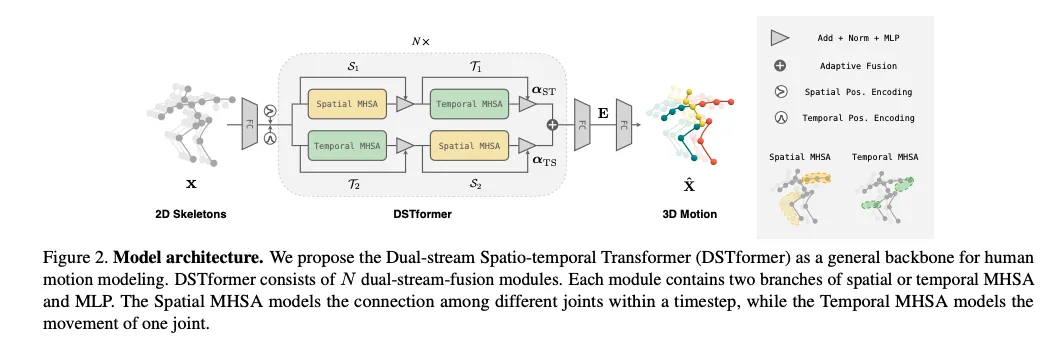
•
input: 2D skeletons x
•
: x로부터의 high dimensional feature(0은 네트워크 depth를 의미함. i=0~N), FC를 거친 후의 feature
•
: learnable spatial positional encoding
•
: learnable temporal positional encoding
1.
에 와 를 추가하여 DTSformer의 입력으로 넣음
2.
DSTformer를 사용하여 (i = )를 얻음
3.
motion representation 를 얻기위해 tanh activation이 포함된 선형 레이어를 에 적용함
4.
3D motion 를 추정하기 위해 선형 transformation을 E에 적용함
1-1. Spatial Block
Spatial Block MHSA: 동일한 timestep에서 관절 사이의 관계를 모델링하는 것이 목표임. 그러므로 서로 다른 timestep의 feature에 병렬적으로 적용됨
1-2. Temporal Block
Temporal Block MHSA: 시간 흐름에 따른 동일한 신체 관절의 관계를 모델링하는 것이 목표임. 각 joint의 temporal feature 에 적용되며, 이것이 spatial dimension에 걸쳐서 병렬화됨
1-3. Dual-stream Statio-temporal Transformer
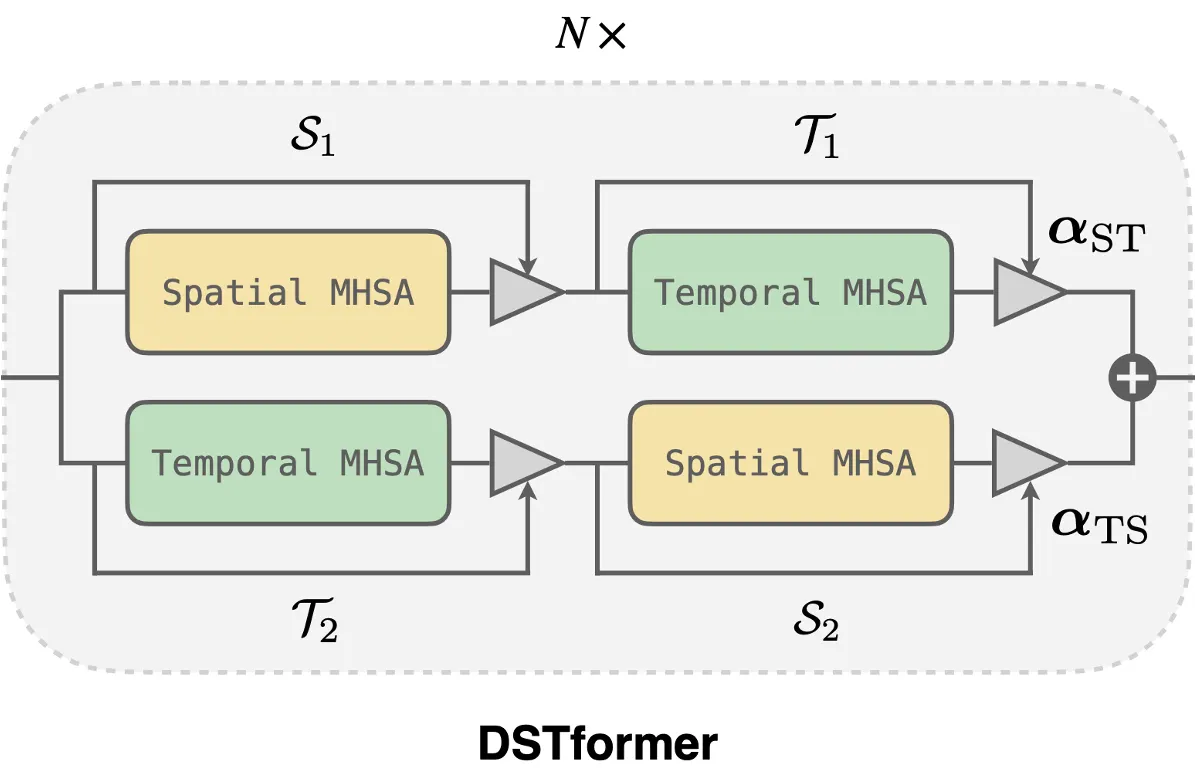
intra-frame(프레임 내의)과 inter-frame(여러 프레임 간의)의 body joint interaction을 포착하는 spatial, temporal MHSA가 주어지면, timestep에 따른 spatial과 temporal 정보를 융합하기 위해 기본 block을 구성함
세 가지 가정을 기반으로 dual-stream 아키텍처를 구성함
1.
두 stream 모두 comprehensive spatio-temporal context를 모델링할 수 있어야 함
2.
각 stream은 각각의 시간적 공간적 측면에서 전문화 되어야 함
3.
input인 spatio-temporal characteristic에 따라 fusion weight이 동적으로 균형을 이루도록 두 stream이 융합되어야 함
spatial MHSA와 temporal MHSA를 서로 다른 순서로 쌓아 두 개의 병렬적인 computation branch를 형성함
두 branch의 output은 attention regressor를 통해 추정된 adaptive weight을 통해 융합됨
이 dual-stream-fusion 모듈을 N번 반복함
2. Unified Pretraining
해당 framework 설계를 위해 해결해야 할 문제는 아래와 같음
1.
보편적인 pretext task로 강력한 motion representation을 학습하는 방법
2.
대규모이며 다양한 형태를 가진 데이터를 모든 종류의 format으로 활용하는 방법
첫 번째 문제의 해결을 위해 이전 연구들의 방향성에 따라 supervision signal을 구성함. 즉, input 일부를 mask 처리한 후 다시 전체를 재구성하도록 함.
가장 먼저 3D motion을 직교투영하여 2D 스켈레톤 시퀀스 x를 추출함. 그리고 2D 시퀀스에 random mask를 취하여 손상시키며 이때 joint-level과 frame-level mask는 특정 확률로 적용됨.
즉, motion encoder를 통해 motion representation 를 얻고, 3D motion 을 재구성함. 그리고 와 GT 3D motion X 사이의 loss인 를 얻음. 이에 추가로 이전 연구들과 동일하게 velocity loss 를 구함
두 번째 문제를 해결하기 위해서는 2D 스켈레톤이 다양한 종류의 모션 데이터에 대한 보편적인 역할을 수행할 수 있다는 점을 활용함. unified pretraining을 위해 in-the-wild RGB 비디오 데이터로부터 2D를 3D로 lifting함. 이때는 2D reprojection loss를 사용함
즉 전체 loss는 아래와 같음
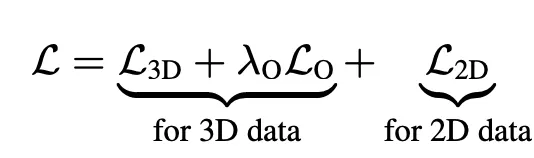
3. Task-specific Finetuning
학습된 feature embedding E는 3D-aware and temporal-aware human motion representation가 됨.
이로부터 얕은 downstream network와 학습을 구현하고 finetune하여 각 task에 맞도록 학습함
1.
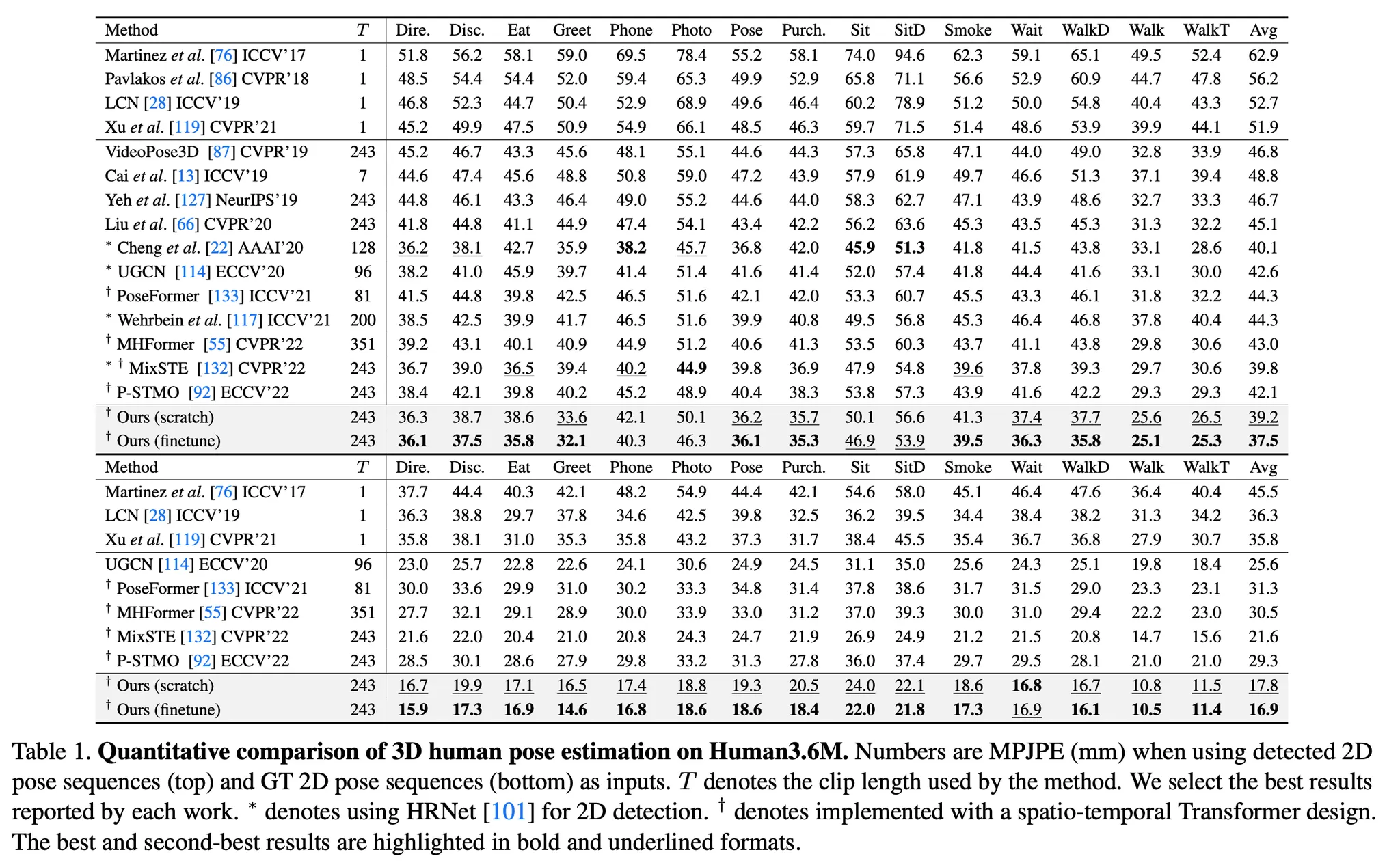
2D-to-3D lifting이 pretext task로 사용되므로 E를 통해 3D Pose Estimation에는 바로 적용될 수 있음
2.
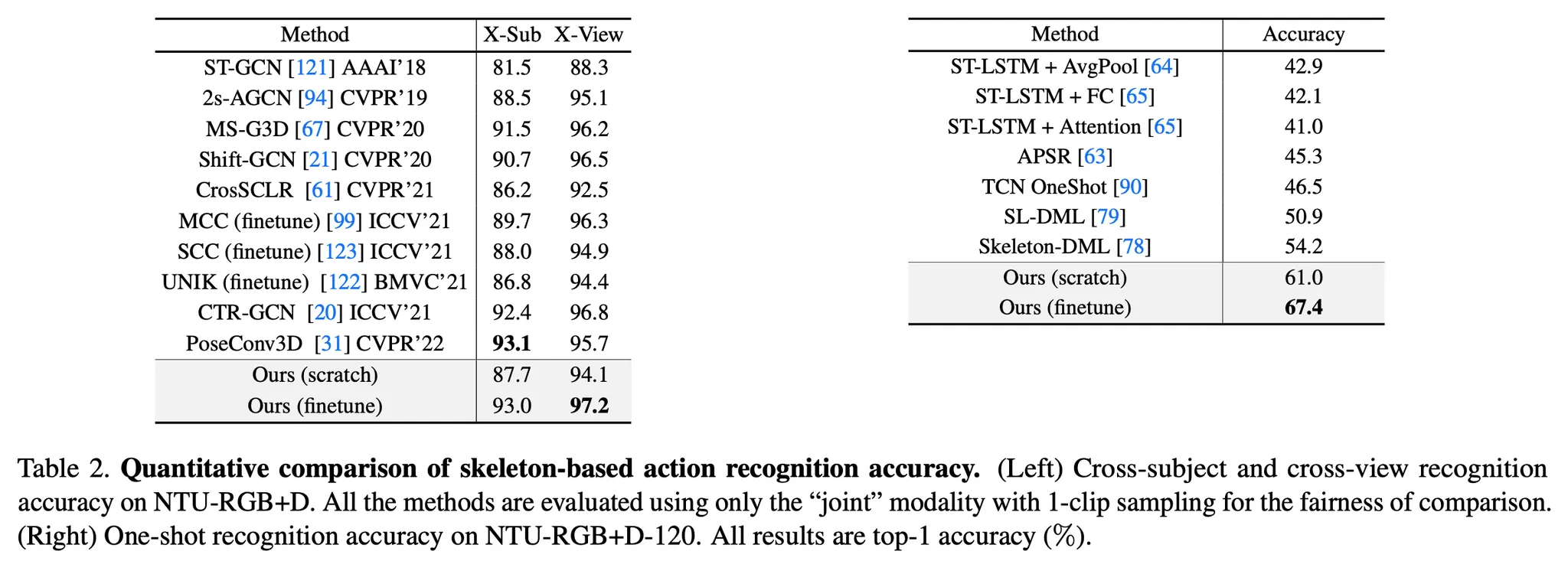
또한 timestep에 따른 스켈레톤을 학습하므로 간단한 MLP를 통해 Skeleton-based Action Recognition을 수행함
3.
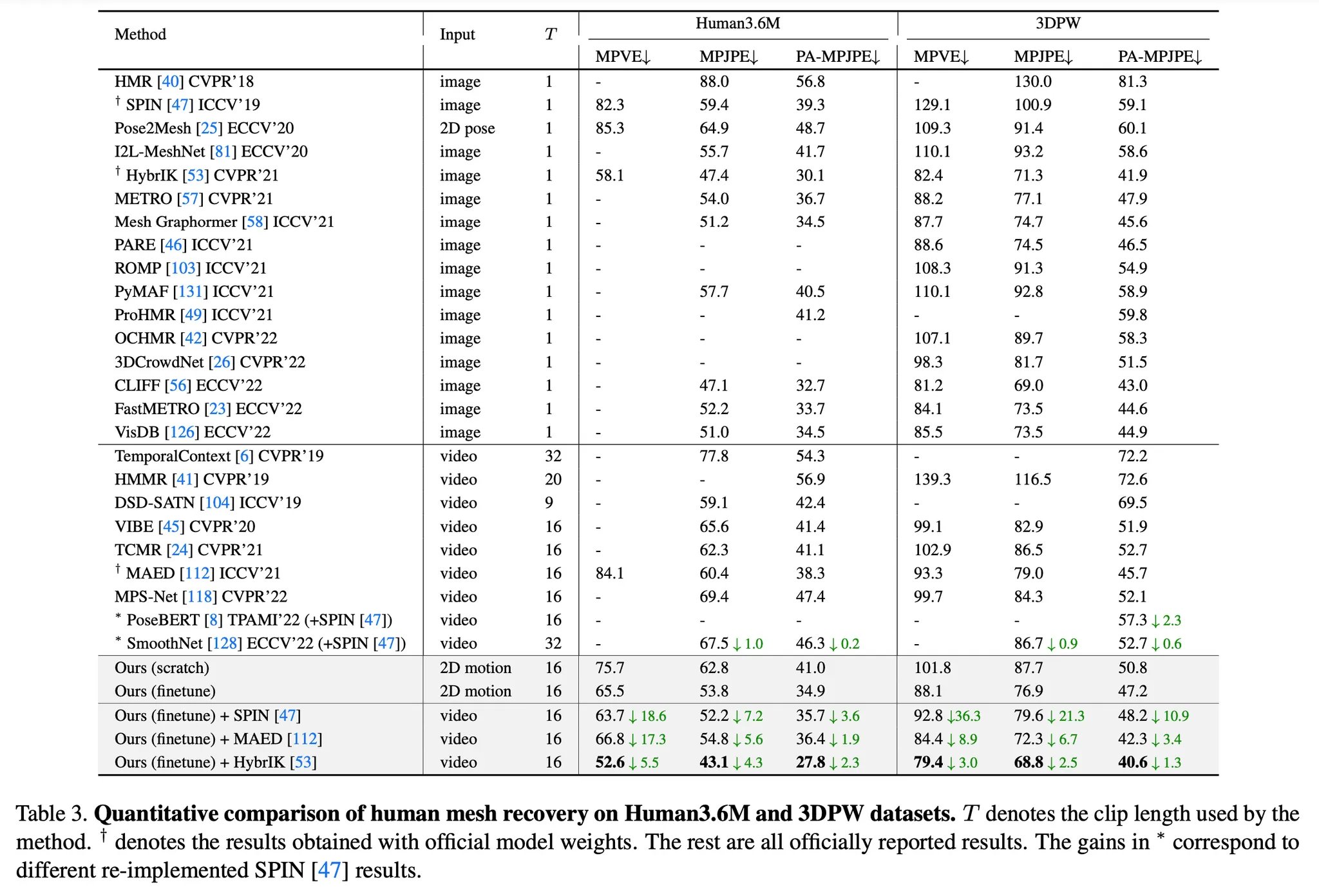
Human Mesh Recovery task를 위해 SMPL을 사용함. 각 프레임에 대한 pose 파라미터를 얻기 위해 motion embedding을 hidden layer가 포함된 MLP의 입력으로 하여 포즈 파라미터 를 얻으며, shape 파라미터를 얻기 위해 temporal dimension에 걸쳐 average pooling을 진행한 후 또 다른 MLP의 입력으로 해서 shape 파라미터 를 얻음. 이때의 loss는 아래와 같음