
Abstract
Introduction
Related Work
Method
OCHMR은 사람이 겹쳐있을 때(occlusion/crowding) top-down 방식과 bottom-up 방식의 강점을 모두 활용한다. 이 섹션에선 본 연구에서 베이스라인으로 활용한 모델을 간단히 설명한다. 그 후 본 연구의 contextual representation인 local centermaps와 global centermaps를 설명하면서 context estimation network에 대해서도 설명할 것이다. 마지막으로 Context Normalization (CoNorm) block과 multi-person losses가 훈련과정에 적용되었을 때 성능이 향상됨을 보일것이다.
Top-down Human Mesh Recovery
Occluded Human Mesh Recovery
본 연구에선 top-down 방식 모델 를 수정하여 아래와 같은 방식으로 여러 메쉬를 추정하는 방식을 제안했다. 이 이미지 에서 보이는 사람의 수라고 하자. 의 숫자는 이미지에서 2차원 관절이 최소 5개 이상은 보이는것을 기준으로 했다. 가 각 사람의 정답 메쉬파라미터라고 하자. 본 연구는 모델 가 개의 인스턴스 를 추정하도록 수정하였다. 이는 모델 를 각 사람마다 독립적인 spatial-context 에서 조건화함으로써 달성하였다. 모델 는 와 를 모두 입력값으로 받아 를 추정하도록 설계하였다. 본 연구는 OCHMR의 단일 인물에 대한 손실값 을 아래와 같이 정의하였다.
추론하는 동안 같은 입력이미지 로 부터 추정된 여러 spatial-context 를 이용하여 메쉬를 추출한다. 몇가지 사람이 겹친 상황에서 top-down 방식의 베이스라인 모델로 단일 이미지 로 부터 다양한 바디메쉬 를 추론하는 것은 어렵다. OCHMR은 spatial-context 를 이용하여 여러 사람이 있는 경우 생기는 바운딩박스의 모호성을 해결하였다.
Global and Local Center Map Estimation

본 연구에서 제안한 top-down 프레임워크는 spatial-context 에 상당부분 의존하고 있다. 명확하고 겹치는 부분에 대해 강건한 표현법(representation)을 정의하는 것은 매우 중요한 문제다. 기존연구에서 영감을 받아 본 연구는 이미지의 spatial-context 를 표현하기 위해 body center를 활용하였다. 특히 번째 context information을 로 표현했고 여기서 은 이미지 에서 모든 개 인스턴스의 body center heatmap이고 는 번째 body center heatmap이다. 은 의 픽셀위치에서 임계방식(thresholding)과 반복방식(iterating)을 통해 계산된다. 는 각 사람에 대한 정보를 모델에게 알려주지만, 는 사람의 주변에 대한 context에 대해 설명하기 때문에 네트워크가 겹친 사람을 구별할 수 있도록 돕는다(→이 부분 해설이 잘 안됨).
body center는 관측가능한 torso 관절(neck, left/right shoulders, pelvis, and left/right hips)의 중심으로 정의된다. 모든 torso 관절이 보이지 않을 경우 중심은 보이는 관절에 대한 평균값이 된다. 본 연구에선 2차원 관절의 정답값을 이용해 body center를 계산하였다. 모든 2차원 body center 정답값의 위치는 크기의 heatmap 형태인 로 변환되어 전체 이미지에서 각 픽셀이 body center일 확률을 표현한다. 추론과정에선 fully-convolution의 인공신경망 을 사용하여 입력이미지 에 대해 을 예측하도록 했다. 는 를 최소화 하는 방향으로 훈련한다. i번째 값 는 channel-wise concatenation을 통해 과 를 합쳐 가 되도록 한다.
Context Normalization Block
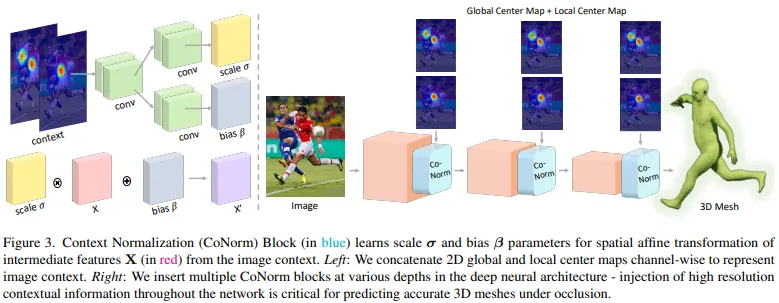
조건화된 입력을 위해 spatial-context를 포함하는 아키텍쳐를 설계하는건 쉽지 않은 문제이다. naive early fusion방식을 이용하면 간단하게 입력이미지 와 spatial-context 를 합칠 수 있다. 유사한 방식으로 later fusion은 적절하게 다운샘플링된 context 를 사용하여 네트워크의 뒤쪽 layer를 합친다. 그러나 두 방식 모두 성능을 올리는덴 실패했다.
본 연구에선 이러한 문제를 해결하기 위해 현재 존재하는 feature 추출용 backbone에 쉽게 적용할 수있는 Context Normalization(CoNorm) block을 소개한다. CoNorm이 conditioning 입력 C를 사용하여 중간 feature map의 정규화를 할 수 있도록 하는것이 핵심 아이디어이다. 딥러닝 모델 P는 입력이미지 I로 부터 여러 메쉬를 예측하기 위한 contextual information을 이용하기 위해 CoNorm block을 사용한다. 배치정규화와 유사하게 CoNorm은 을 기반으로 한 네트워크의 중간 feature에 아핀변환(affine transformation)을 적용하여 신경망의 출력에 영향을 주기 위해 학습시킨다.
를 딥러닝 모델 의 중간 feature라 하자. CoNorm block은 context 에서 과 연산으로 구성돼있다. 는 와 같은 2차원 해상도 를 가지도록 다운샘플링 된다.
는 를 차원의 잠재공간 에 매핑시킨다. 과 는 잠재벡터 를 를 예측하기 위해 사용한다. 예측된 와 는 출력값 에 element-wise 연산을 적용하여 중간 feature 를 정규화 하기 위해 사용된다.
class CoNorm(nn.Module):
def __init__(self, num_channels, hidden_channels=128):
"""
CoNorm Block for Occluded Human Mesh Recovery
num_channels: number of channels in the intermediate feature X
hidden_channels: K, dimensionality of the latent space of the CoNorm block
"""
super(CoNorm, self).__init__()
self.phi_latent = nn.Sequential(
nn.Conv2d(2, hidden_channels, kernel_size=3, padding=1),
nn.ReLU()
)
self.phi_scale =
nn.Conv2d(hidden_channels, num_channels, kernel_size=3, padding=1)
self.phi_bias =
nn.Conv2d(hidden_channels, num_channels, kernel_size=3, padding=1)
def forward(self, X, context):
"""
X: intemediate feature of the segmentation backbone
context: local and global centermap concatenated channelwise
"""
context =
F.interpolate(context, size=X.size()[2:], mode='bilinear', align_corners=False)
lambda_ = self.phi_latent(context)
scale = self.phi_scale(lambda_)
bias = self.phi_bias(lambda_)
X_prime = X * scale + bias
return X_prime
Python
복사
CoNorm block 코드
Multi-Person Losses
여러사람이 있는 이미지에서 모델 는 겹치거나 일관되지 않은 깊이값 순서(depth ordering)의 메쉬를 추정하곤 한다. 이를 해결하기 위해 본 연구에선 두가지 multi-person losses를 사용하였다. 이는 아래 그림과 같은 interpenetration loss와 depth-ordering loss에 해당한다.
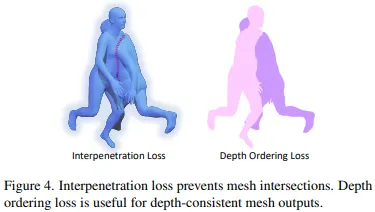
Interpenetration Loss. 를 3차원 공간에서 Signed Distance Field(SDF)를 수정한 값이라고 하자. SDF는 내부는 외부는 로 그리고 edge에 갈 수록 에 가깝게 되는 거리함수이다. 가령 아래그림와 같은 상황이라고 가정하자.
이 때 SDF는 아래 그림과 같다.

는 SDF를 수정하여 3차원 메쉬 안에 있는 점은 모두 양수고 메쉬 표면으로 부터의 거리에 비례하도록 하며 그 외 나머지 영역은 0으로 만들었다. 본 연구에선 이를 활용하여 구분된 거리 필드 를 각 메쉬 에 대해 계산하였다. pairwise interpenetration loss 는 메쉬 와 메쉬 사이의 손실값으로 아래와 같이 정의하였다.
Depth-ordering Loss. 본 연구에선 depth-ordering loss 를 정의하였다. COCO 데이터에서 사용가능한 세그멘테이션 맵의 정답값을 이용하는게 주된 아이디어다. 이를 위해 미분가능한 렌더러를 이용하여 이미지 평면에 모든 메쉬와 이에 대응하는 깊이맵을 합성하였고 이미지 의 정답값 세그멘테이션 맵에 기반한 점의 위치를 최적화 하는 방식을 사용하였다.
최종적으로 모델 는 손실값 을 최소화 하도록 학습하게 된다.
Experiments
Implementation Details
OCHMR 공정한 비교를 위해 모델 의 백본은 ResNet-50으로 context estimator 의 백본은 HRNet-W32으로 했다. 본 연구에선 백본의 4개의 ResNet block의 후미에 CoNorm block을 넣었다. 또한 모든 실험에서 CoNorm의 잠재공간(latent space)의 차원 를 128차원으로 설정했다. 입력데이터는 로 했고 비율을 같게 유지하기 위해 제로패딩을 활용하였다. 기존 연구에 영감을 받아 local/global centermaps에 6픽셀의 가우시안 블러를 적용하였다. 손실값의 가중치는 , , 로 설정하여 각 손실값들이 같은 범위의 크기를 가지도록 설정하였다. 마지막으로 local/global centermap의 임계값은 0.3으로 설정하였다.
Training Datasets 학습을 위해 MPI-INF-3DHP, COCO, MPII, LSP-Extened 데이터셋을 활용하였으며 라이센스 문제로 Human3.6M은 활용하지 않았다. MPI-INF-3DHP에서 SMPL의 GT데이터를 활용하였고 COCO, MPII, LSP-Extended에선 2차원 데이터들을 활용하였다. 또한 의 계산을 위해 COCO 데이터셋의 세그멘테이션 데이터를 활용하였다.
Evaluation Benchmarks 야외의 여러사람으로 이루어진 비디오로 2D/3D 어노테이션이 존재하기 때문에 3DPW-PC를 3D 메쉬/관절의 평가를 위한 메인 데이터셋으로 선정하였다. 3DPW-PC는 3DPW 중 사람과 사람으로 가려진 영역이 존재하는 데이터를 뽑은것이다. 또한 Crowdpose와 OCHuman 데이터셋을 활용하여 야외군중의 2차원 데이터셋에서의 평가도 진행하였다. 마지막으로 3DPW와 COCO 데이터셋을 통해 일반적인 데이터셋에서의 평가도 진행하였다.
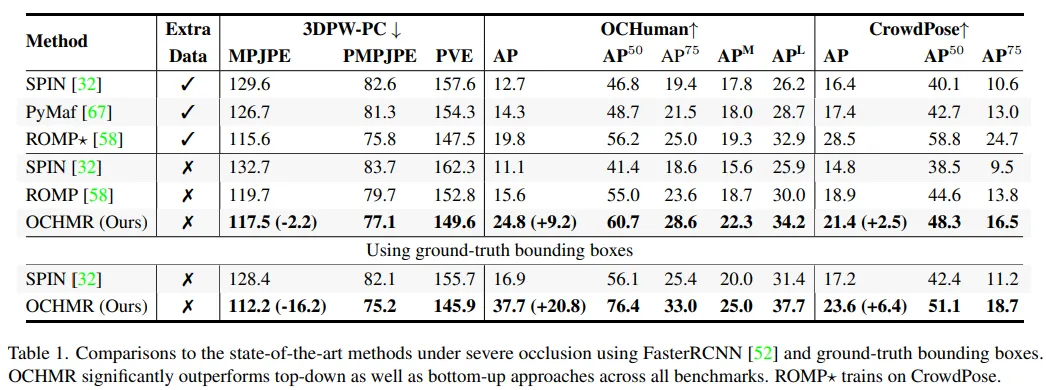
Evaluation Metrics 3차원 데이터셋에선 MPJPE, PMPJPE와 PVE를 평가지표로 선정하였다. 또한 사람이 겹친 이미지에서의 정확도 평가를 위해 다양한 OKS에 관한 를 구했다. 바운딩 박스는 Faster R-CNN을 활용하여 구하였다.
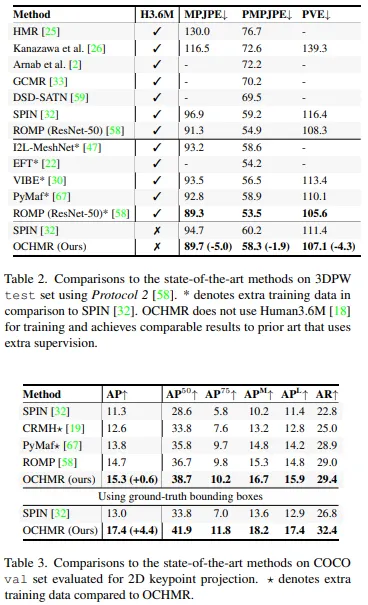
Comparison to the State-of-Art
Occlusion benchmarks 겹치는 이미지에서의 본 모델의 안정성을 확인하기 위해 여럿 겹치는 이미지에서 평가를 진행하였다. 먼저 사람들 사이의 겹치는 상황의 평가를 위한 데이터셋으로 3DPW-PC, OCHuman, Crowdpose를 선정하였고 이에 대한 결과는 1번 표에 나와있다. 또한 아래 Conclusion의 결과예시를 보면 본 모델이 top-down 모델인 SPIN이나 bottom-up 모델인 ROMP 보다 더 강건한 모델임을 확인할 수 있다. 또한 GT 바운딩 박스를 사용했을 때 결과를 보면 고해상도의 이미지를 입력으로 사용했을 때 global/local centermap이 겹치는 이미지를 다루는데 매우 중요한 역할을 함을 확인할 수 있다.
General benchmark 본 연구에선 3DPW와 같은 자주 쓰이는 벤치마크 데이터셋에서도 평가를 진행하였다. OCHMR은 겹치지 않는 이미지에서도 큰 성능 하락이 없다. 오히려 SPIN의 MPJPE 오류와 비교했을 때 5mm 정도의 성능 향상을 보였다. 별도의 추가 데이터 학습 없이 본 모델은 ResNet-50을 백본으로 사용하는 ROMP와는 유사한 성능을 보였다. 또한 COCO 데이터셋에서도 좋은 성능을 보임을 확인했다.
Analysis
본 연구에선 GT 바운딩박스를 활용하여 3DPW-PC에서 평가를 통한 분석을 진행하였다.
CoNorm Block Architecture early fusion과 late fusion에 대해 CoNorm block의 평가를 진행하였다.
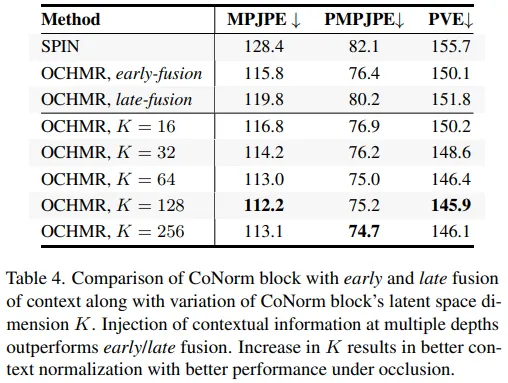
early fusion에선 channel-wise concat을 통해 입력이미지, global centermap, local centermap을 합쳤다. late fusion에선 세번째 ResNet block 후 다운샘플링된 context information인 중간 feature를 합쳤다. 본 실험에서 CoNorm block 형식의 여러 깊이에서의 고해상도 context information을 넣는것이 겹치는 이미지에서 정확한 사람의 메쉬를 추정하는데 중요한 역할을 함을 확인하였다. 또한 본 연구에선 OCHMR을 백본으로 사용했을 때 4개의 CoNorm 블록에서 잠재공간(latent space)의 차원 를 다양하게 설정하여 실험을 진행했다. K가 증가할 수록 SPIN 모델과 비교하여 성능이 증가하는 것을 확인했으며 모델의 정확도와 오버헤드를 고려하여 일 때 균형있는 성능을 확보할 수 있음을 확인하였다.
Effect of Multi-Person losses 이나 등의 multi-person losses의 영향도를 확인 하기 위한 실험을 진행하였다.
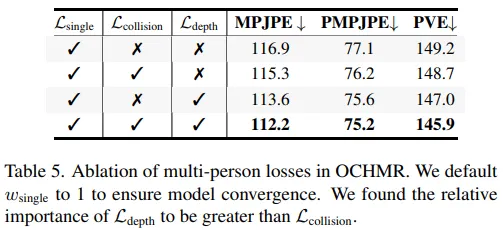
결과 표는 위와 같으며 이를 통해 두 손실함수를 모두 사용했을 때 가장 좋은 성능을 보임을 확인했으나 보다 가 좀 더 영향을 미침을 확인하였다. 또한 multi-person losses 사용하지 않은 손실함수()만을 사용해도 SPIN보다는 성능이 좋게 나왔다.
Choice of Context CoNorm block을 사용하면 다양한 context representation으로 네트워크 P를 조정할 수 있다. 결과표는 아래와 같다.
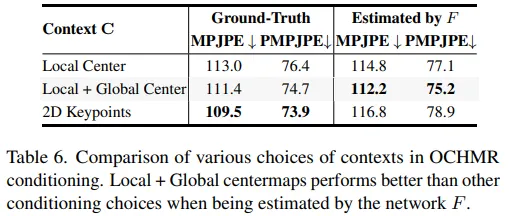
위 표에선 GT 바운딩 박스를 사용했을 때와 네트워크 F를 사용했을 때 각 context의 영향을 보인다. context는 local centermap 사용했을 때, local centermap과 global centermap을 같이 활용했을 때, 2D keypoint를 활용했을 때로 구성하여 실험을 진행하였다.
local centermap과 global centermap을 비교했을 때 global centermap이 겹치는 상황에서 더 좋은 영향을 주었음을 확인하였다. 흥미로운건 GT 2D keypoint를 활용했을 때 가장 높은 성능을 보였다는것이다. 그러나 GT keypoint를 사용할 수 없을 땐 centermap들을 활용하는게 더 높은 성능을 보였다.
Limitations OCHMR은 여러 단계로 이루어진 top-down 모델이기 때문에 실시간성이 떨어진다. 물론 OCHMR이 여러 사람이 있을 때 겹치는 현상에 대해 높은 성능향상을 보였으나 여전히 다른 오브젝트에 의해 가려진 상황에서는 한계를 보였다. 또한 이런 특수상황에 대한 훈련데이터가 적어 극단적인 포즈나 쉐입에 대해선 한계를 보였다. 이후엔 이러한 다양한 겹치는 상황을 다루기 위해 OCHMR을 활용해볼것이다.
Conclusion
대부분의 top-down 방식은 단일 subject를 입력으로 받고 이 때문에 사람과 사람으로 겹치는 상황에선 낮은 성능을 보여싿. 이를 위해 본 연구에선 OCHMR라 하는 군중 상황에서 여러 사람에 의해 겹쳐지는 이미지를 다루기 위한 새로운 top-down 모델을 제시하였다. 본 모델의 핵심은 이미지로부터 오는 공간적인 context를 local centermap과 global centermap을 통해 겹쳐지는 사람들로 인한 모호성을 효율적으로 줄이려 했다. 본 연구에선 Contextual Normalization(CoNorm) block을 제안하며 기존 이는 top-down 방식에 쉽게 적용될 수 있다. OCHMR은 bottom-up 방식의 영향을 받았으나 top-down 방식과 bottom-up 방식의 장점을 유지하여 여러 사람에 의해 겹치는 부분이 발생하는 이미지에서도 좋은 성능을 보였다.