

본 문서에선 본격적인 CUDA 프로그래밍을 배우기 전에 기초가 되는 내용들을 소개합니다.
•
CPU-only와 GPU-accelerated 어플리케이션 연산과정 비교
•
커널, 쓰레드, 블록, 그리드 개념 설명
•
Grid-stride loops 방식 설명
CUDA(Computed Unified Device Architecture)란?
NVIDIA에서 개발한 범용 컴퓨팅을 위해 GPU를 간단하고 우아하게 사용하는 병렬 컴퓨팅 플랫폼 및 프로그래밍 모델이다. CUDA를 통해 개발자는 GPU의 성능을 활용하여 연산의 병렬처리를 효과적으로 할 수 있게 된다.
GPU-accelerated vs. CPU-only Applications

CPU-only 어플리케이션의 경우 위의 그림과 같이 순차적으로 initialize, performWork, verifyWork를 수행한다.
먼저 어플리케이션은 데이터를 CPU(정확히는 RAM)에 할당하는 initialize를 진행한다. 그리고 이를 이용하여 연산하는 과정인 performWork을 CPU에서 거친다. 연산이 끝나면 결과를 저장하고 확인하는 과정 verifyWork를 진행한다. 이 모든 연산은 위 그림과 같이 전부 CPU단에서 처리되게 된다.
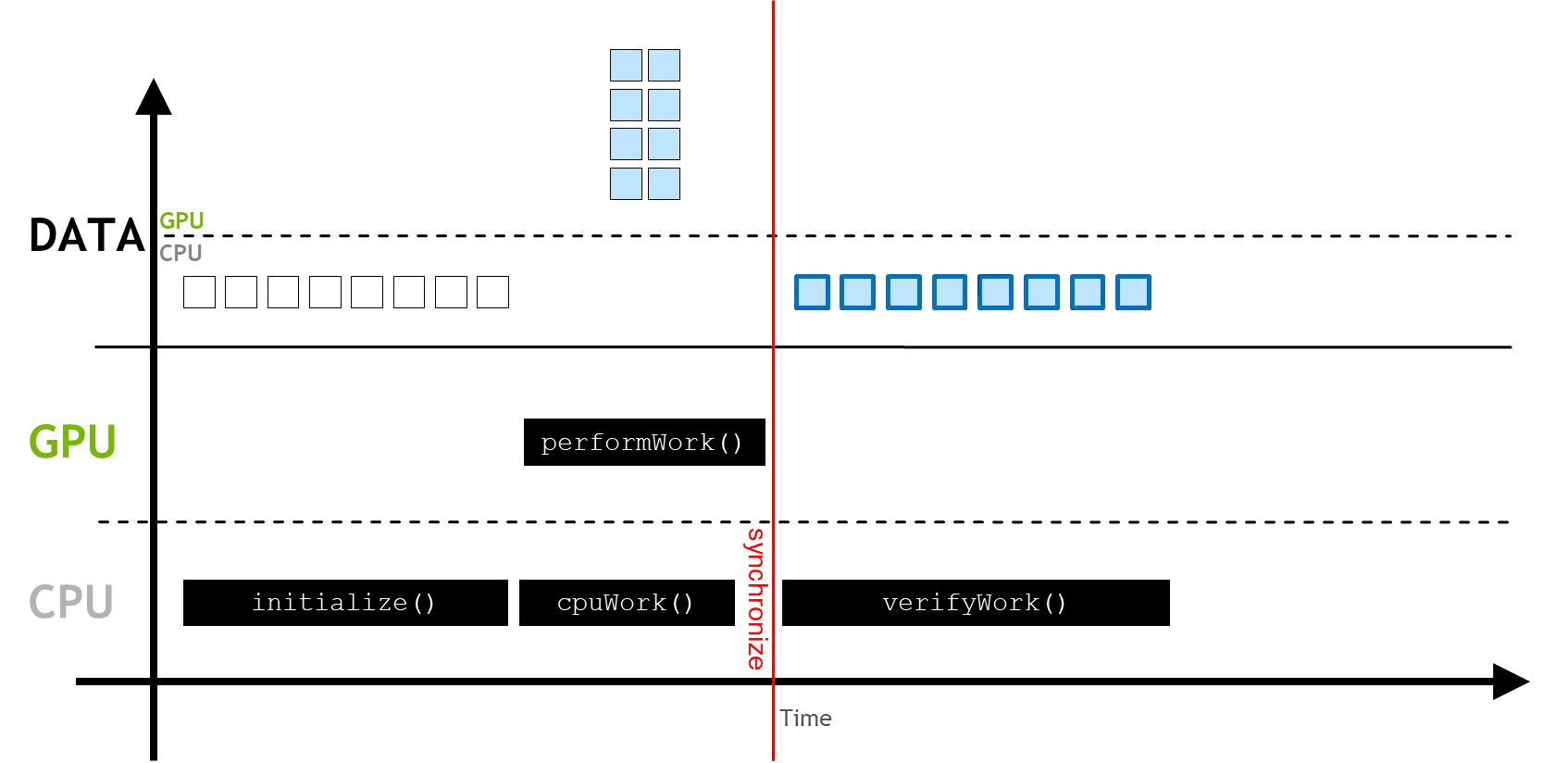
GPU-accelerated 어플리케이션의 경우 위 그림과 같이 연산을 진행한다. CPU-only 어플리케이션과 마찬가지로 initialize과정을 먼저 진행하는데 이 때 cudaMallocManaged 또는 cudaMalloc 함수를 활용하여 CPU에서 선언된 변수와 같은 크기로 GPU에 메모리를 할당한다(두 함수의 차이는 이후에 다시 설명한다). 그 후 CPU에서 선언된 변수를 GPU에서 연산할 수 있도록 메모리를 복사한다. 복사된 변수를 이용하여 GPU에서 performWork과정을 통해 연산하며 이 과정은 CPU와 비동기적으로 진행되기 때문에 위 그림과 같이 GPU가 연산을 하는 동안 CPU에서도 동시에연산 진행이 가능하다(cpuWork). CPU 코드는 cudaDeviceSynchronize 함수를 통해 GPU에서의 연산이 완료될 때 까지 대기하다 동기화를 할 수 있다. 연산이 완료되면 GPU의 연산값 데이터를 다시 CPU에 저장하게 된다.
CUDA Kernel Execution
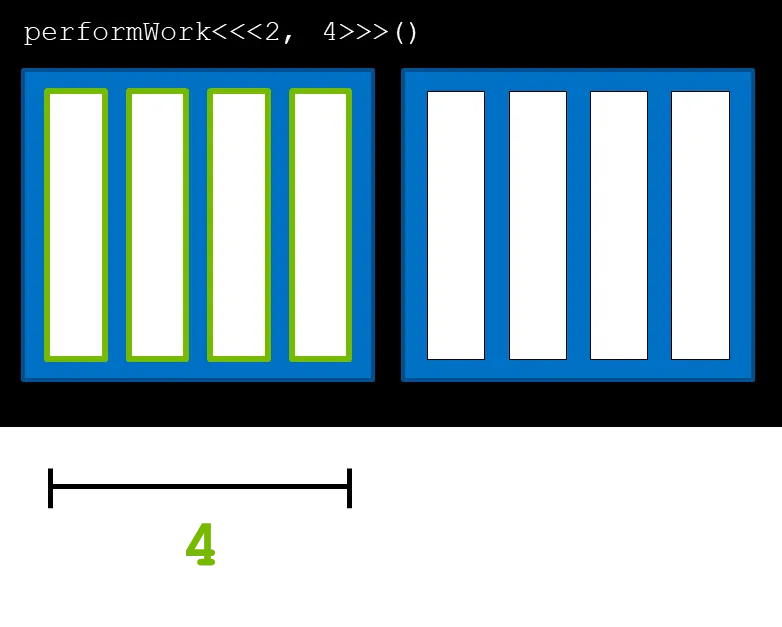
GPU는 기본적으로 쓰레드(thread) 단위로 변수를 저장한다.

위 그림에서 초록색으로 표기된 하얀색 네모박스는 쓰레드를 의미한다. 즉, 위 작업의 경우 총 8개의 쓰레드에서 진행됨을 의미한다.
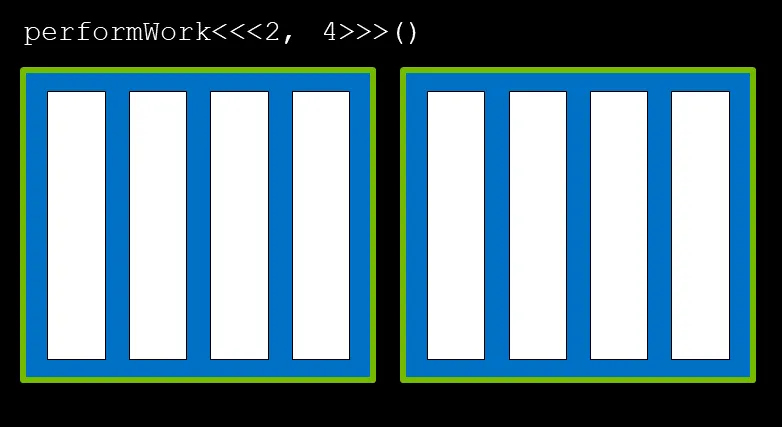
이번엔 블록(block)에 대해 알아보자. 블록은 위 그림에서 초록색으로 표시된 파란 블록을 의미한다. 블록은 여러개의 쓰레드를 구성하는 단위이며 위 그림에선 4개의 쓰레드로 이루어진 2개의 블록이 존재한다.
마지막으로 여러 블록을 모은 단위를 그리드(grid)라 하며 위 그림에선 두 개의 블록이 모여 하나의 그리드를 구성하게 되어있다.
위와 같은 그림처럼 블록과 쓰레드를 구성하기 위해선 아래와 같이 코드를 작성한다.
// 함수 뒤에 세 개 짜리 꺽쇠를 이용해 쓰레드와 블록수를 선언한다.
// 첫 번째 인수는 그리드에서 블록의 수, 두 번째 인수는 블록에서 쓰레드 수다.
// 형식: 함수<<<블록수, 쓰레드수>>>(파라미터...)
performWork<<<2, 4>>>()
// GPU 연산이 끝날 때 까지 대기(동기화)
cudaDeviceSynchronize();
C++
복사
위 와 같은 GPU함수(performWork)를 커널(kernel)이라고 부른다. 커널은 앞에서 선언한 것 처럼 꺽쇠를 통해 선언한대로 블록수와 쓰레드수를 구성하여 실행된다. 또한 모든 블록은 같은 쓰레드 수를 갖는다.
CUDA-Provided Thread Hierarchy Variables
위 과정을 통해 커널이 정의되면 CUDA에서 thread, block, grid라는 변수를 제공하게 된다.
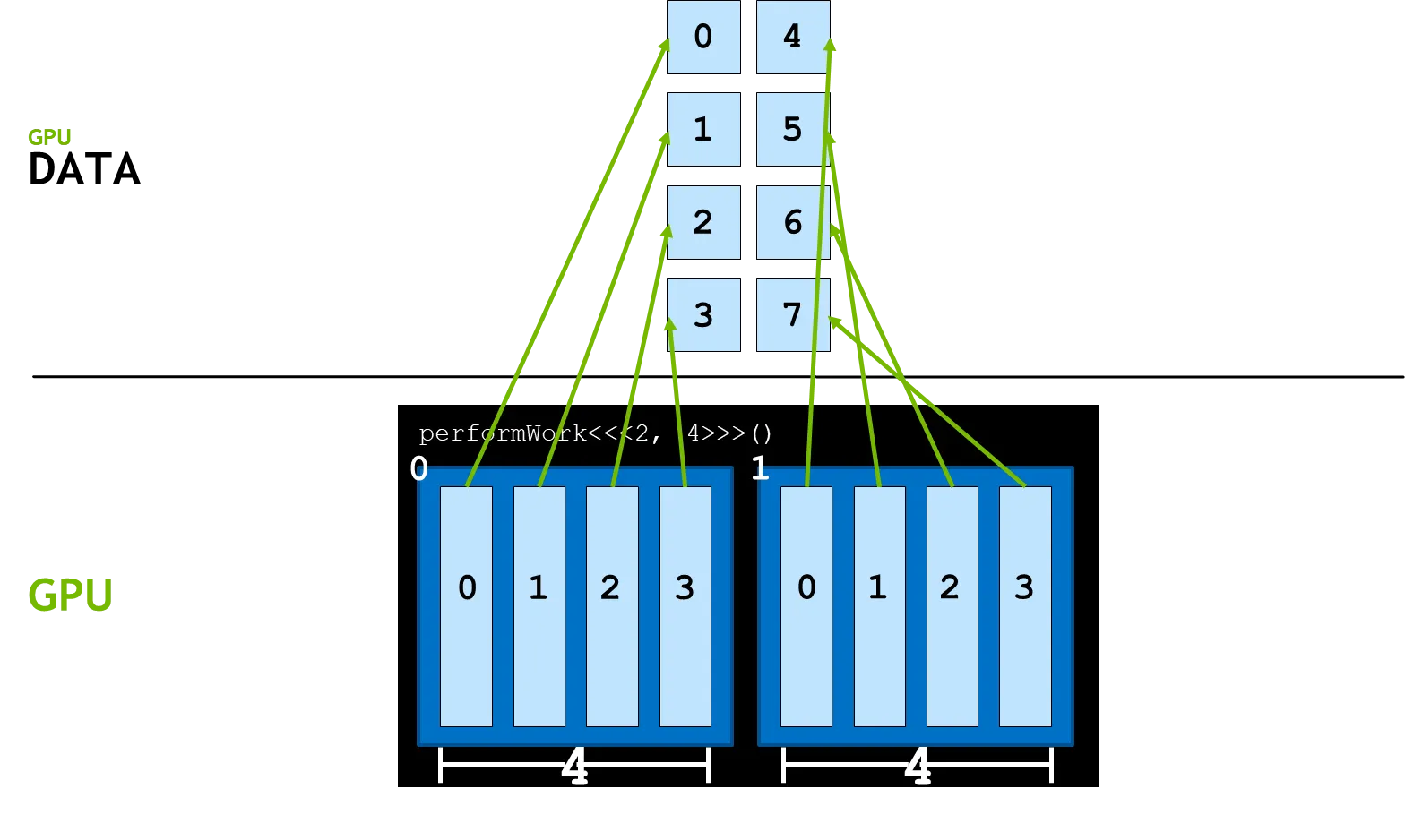
gridDim.x는 그리드 안의 블록의 수를 의미한다. 즉, 아래 그림에서 gridDim.x는 2 이다.
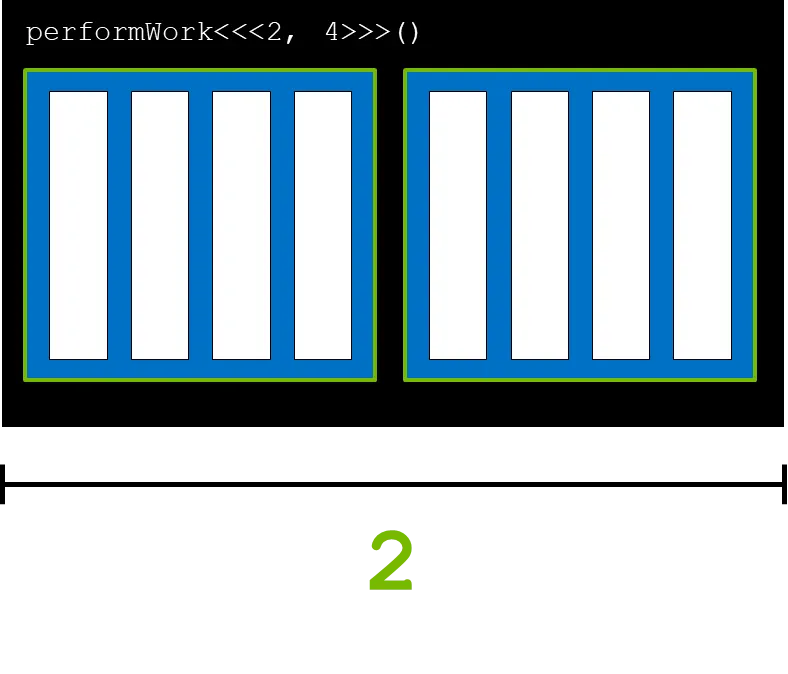
blockIdx.x는 그리드 안에 선언된 블록의 인덱스를 의미한다. 블록 인덱스 0을 가져오면 아래 그림과 같이 첫번째 블록의 인덱스를 가르키게 된다. 마찬가지로 블록 인덱스가 1이면 옆의 블록을 의미한다.
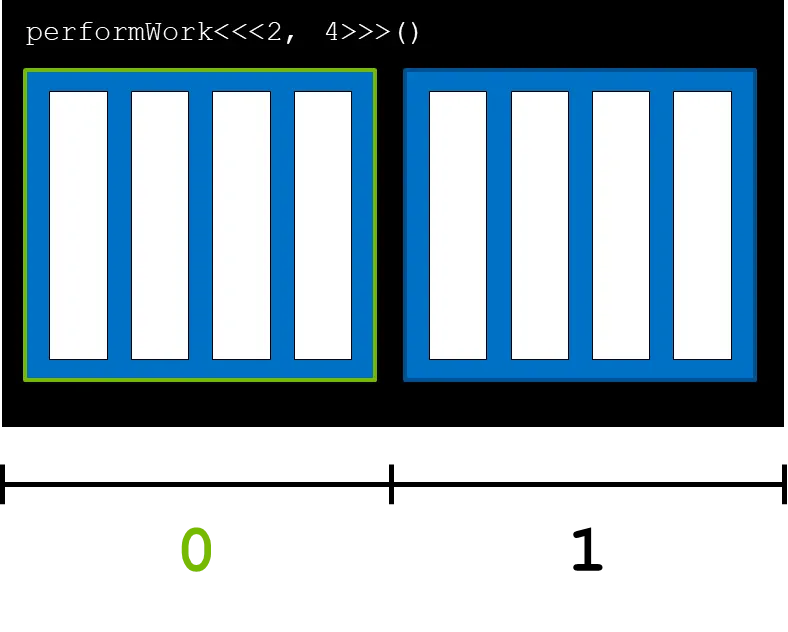
blockDim.x는 블록안의 쓰레드 수를 반환한다. 아래 그림의 경우 위에서 블록의 쓰레드 수를 4라고 했으므로 blockDim.x는 4를 반환하게 된다.
threadIdx.x는 블록 안에 있는 쓰레드의 인덱스를 의미한다. 0번 쓰레드는 아래 그림과 같다.

이 들을 이용하여 아래 코드와 같은 방법으로 블록 인덱스와 쓰레드 인덱스를 통해 데이터 인덱스에 접근 할 수 있게 된다.
// 데이터 인덱스
int tid = blockIdx.x * blockDim.x + threadIdx.x;
C++
복사
Grid Size Work Amount Mismatch
이상적인 상황에선 아래 그림과 같이 모든 데이터가 각 GPU 쓰레드에 모두 할당되게 된다.
그러나 아래와 같이 데이터보다 쓰레드의 개수가 많을 경우를 고려해보자.
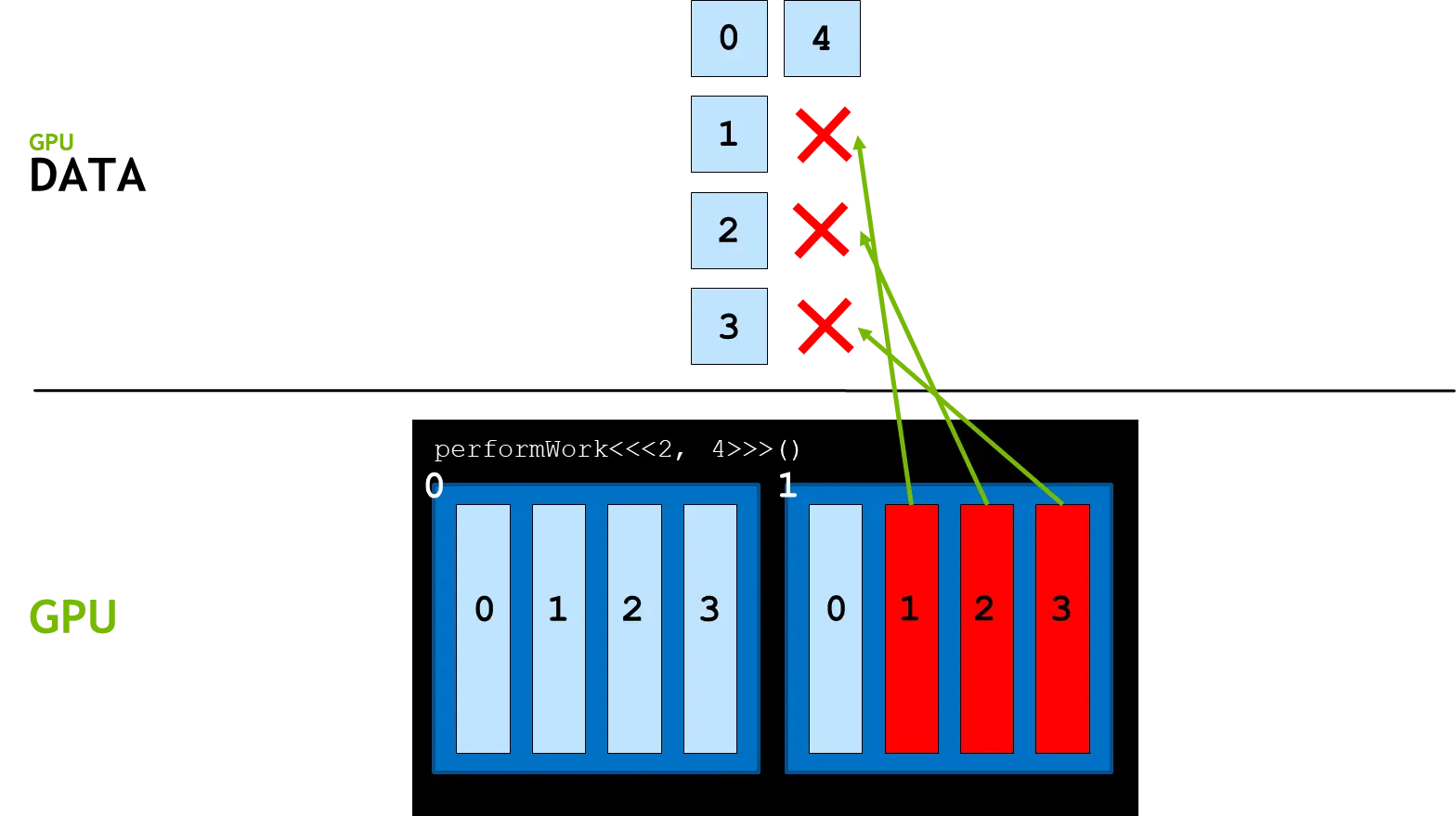
이 때 그림과 같이 데이터가 할당되지 않은 쓰레드가 생기게 되어 런타임 에러(runtime error)가 발생한다. 때문에 blockIdx.x * blockDim.x + threadIdx.x를 통해 계산된 데이터 인덱스가 데이터의 크기보다 작은지 확인해줘야 한다.
Grid-Stride Loops
이번엔 반대로 쓰레드의 개수보다 데이터의 크기가 더 큰 상황을 가정하자. 이를 위한 예시로 아래와 같이 크기가 인 두 개의 배열을 더하는 커널을 작성하였다.
__global__ 키워드는 해당 함수가 GPU에서 연산되는 함수(커널)임을 지정하는 연산기호다.
또한 일반적으로 CPU에서 연산하는 코드를 host 코드라 하고 GPU에서 연산하는 코드를 device 코드라 한다. 추가로 커널의 반환 형식은 반드시 void여야 한다.
__global__
void add(int n, float* x, float* y)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
y[i] = x[i] + y[i];
}
C++
복사
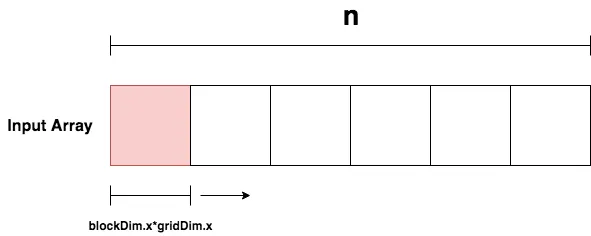
이 경우 데이터의 크기 이 이용가능한 쓰레드의 수를 넘어갈 경우 다룰 수 가 없게된다. 이 같은 경우는 아래 그림과 같은 상황이다.
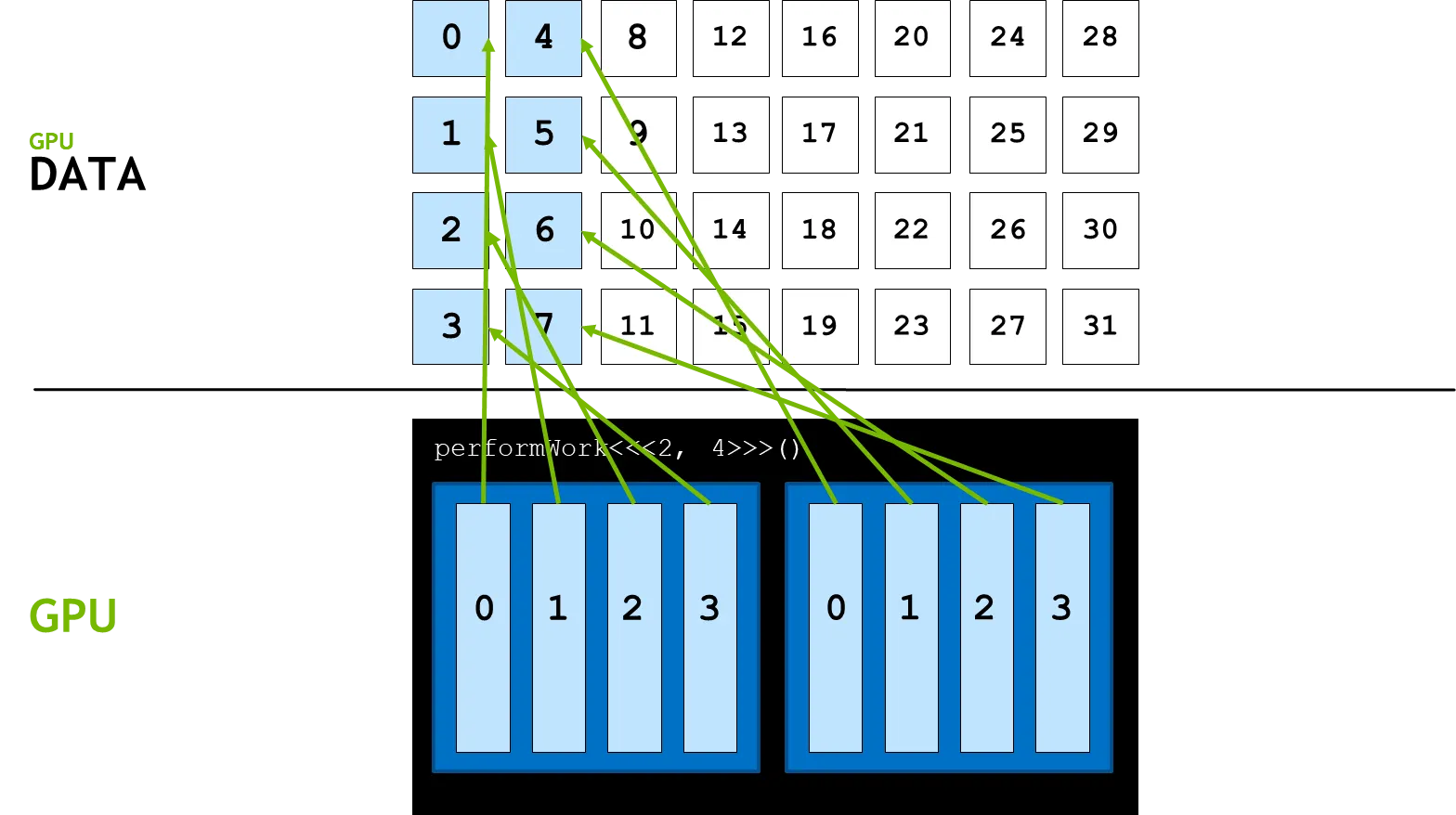
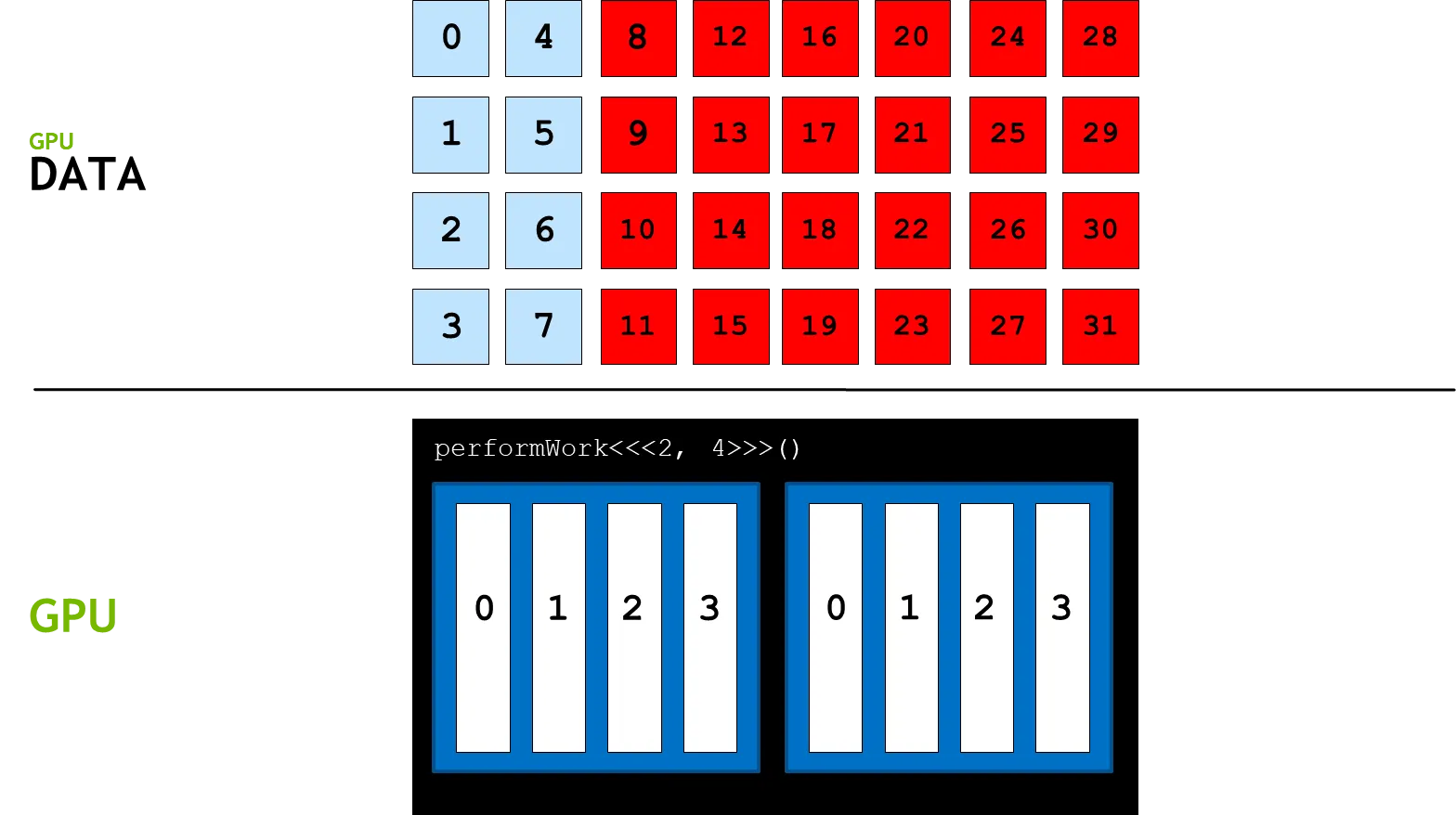
데이터의 크기 이 32이지만 사용가능한 쓰레드의 수가 8이므로 나머지 24개의 데이터는 연산이 불가능하게 된다. 이 부분을 해결하기 위한 프로그래밍 방법론을 grid-stride loop라 한다.
grid-stride loop 과정은 아래와 같다.
grid-stride loop 과정
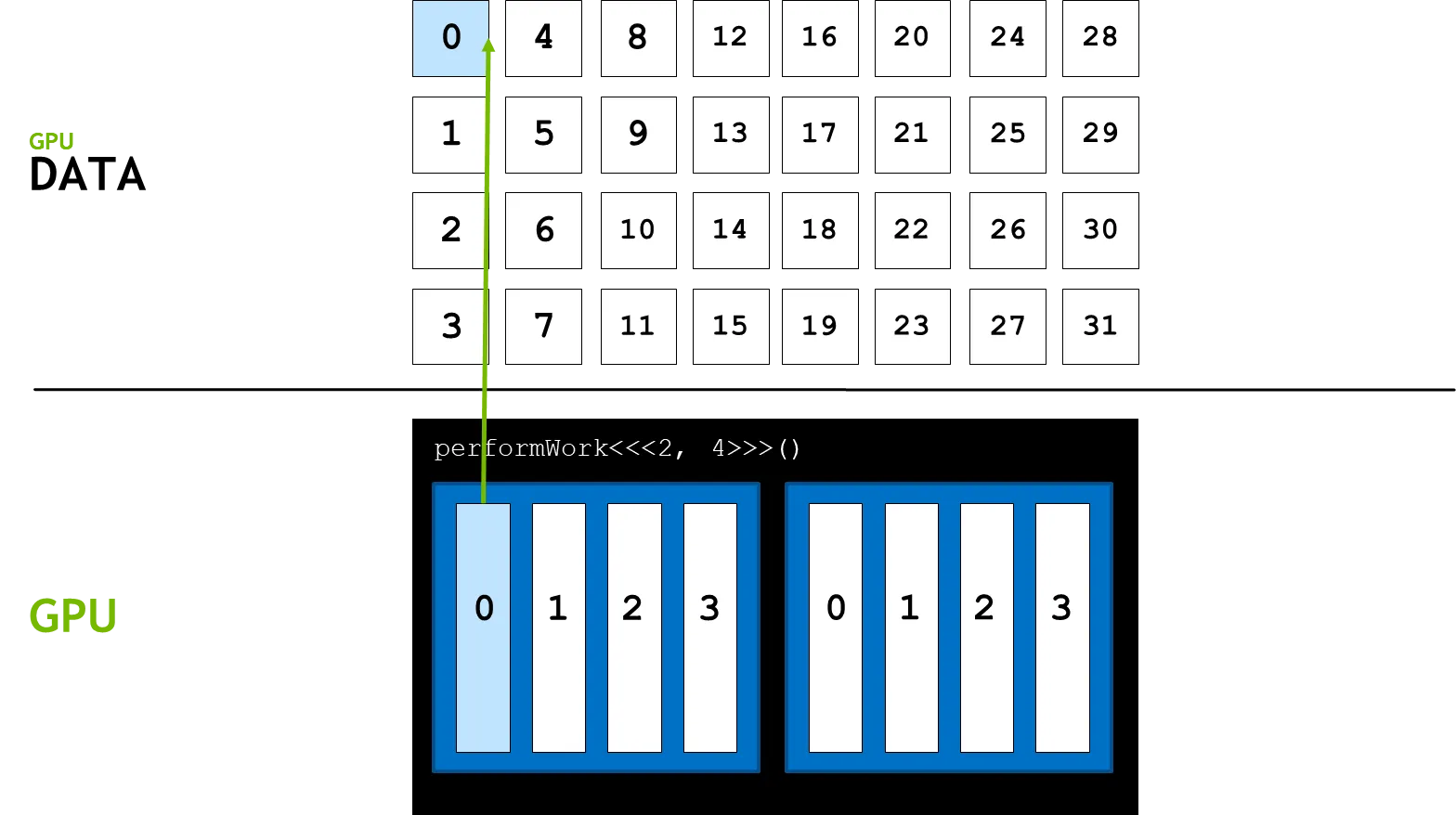
1.
기존 방법과 같이 블록의 첫 번째 쓰레드에 접근한다.(threadIdx.x + blockIdx.x * blockDim.x)
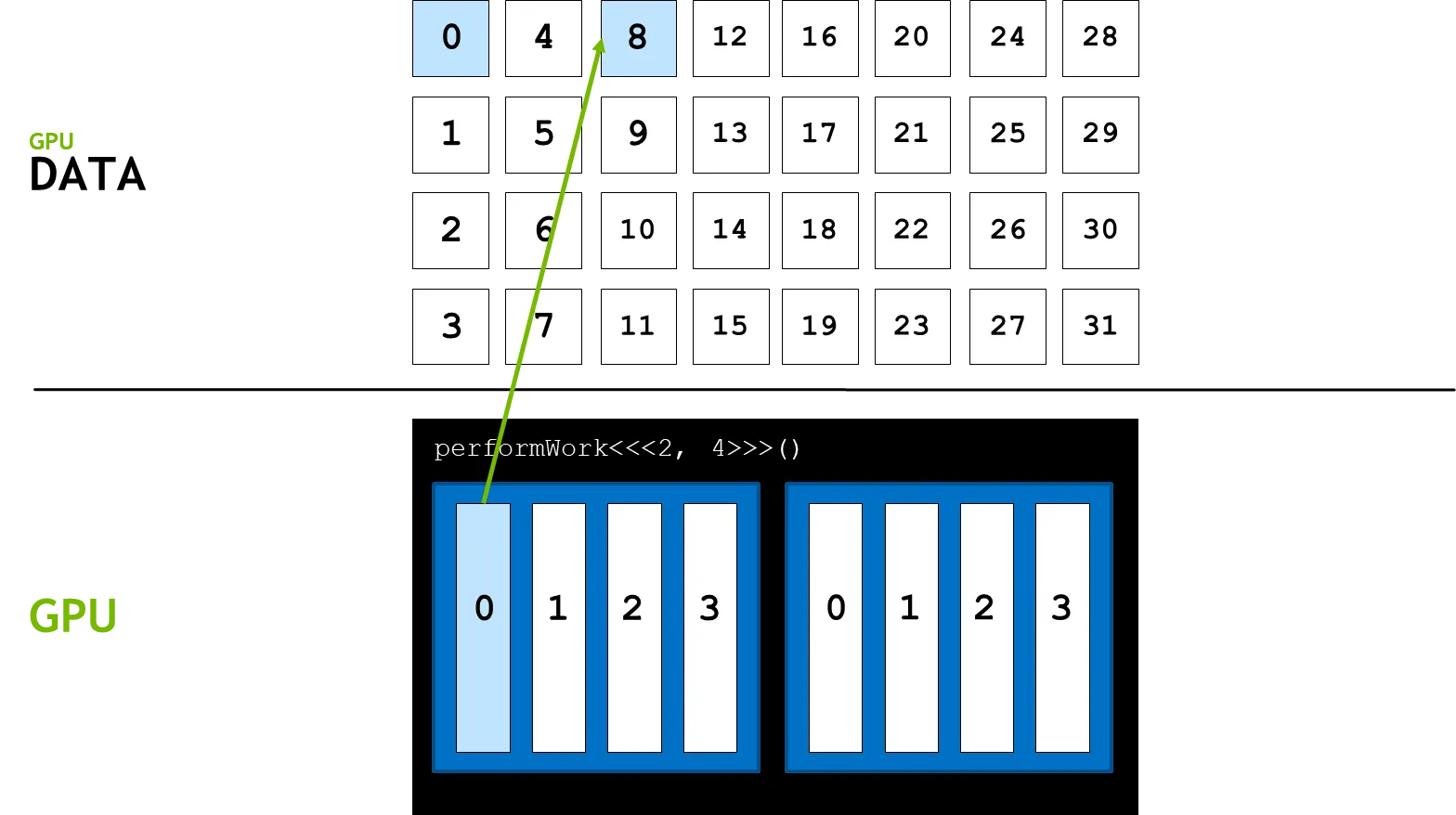
2.
연산을 진행한다.
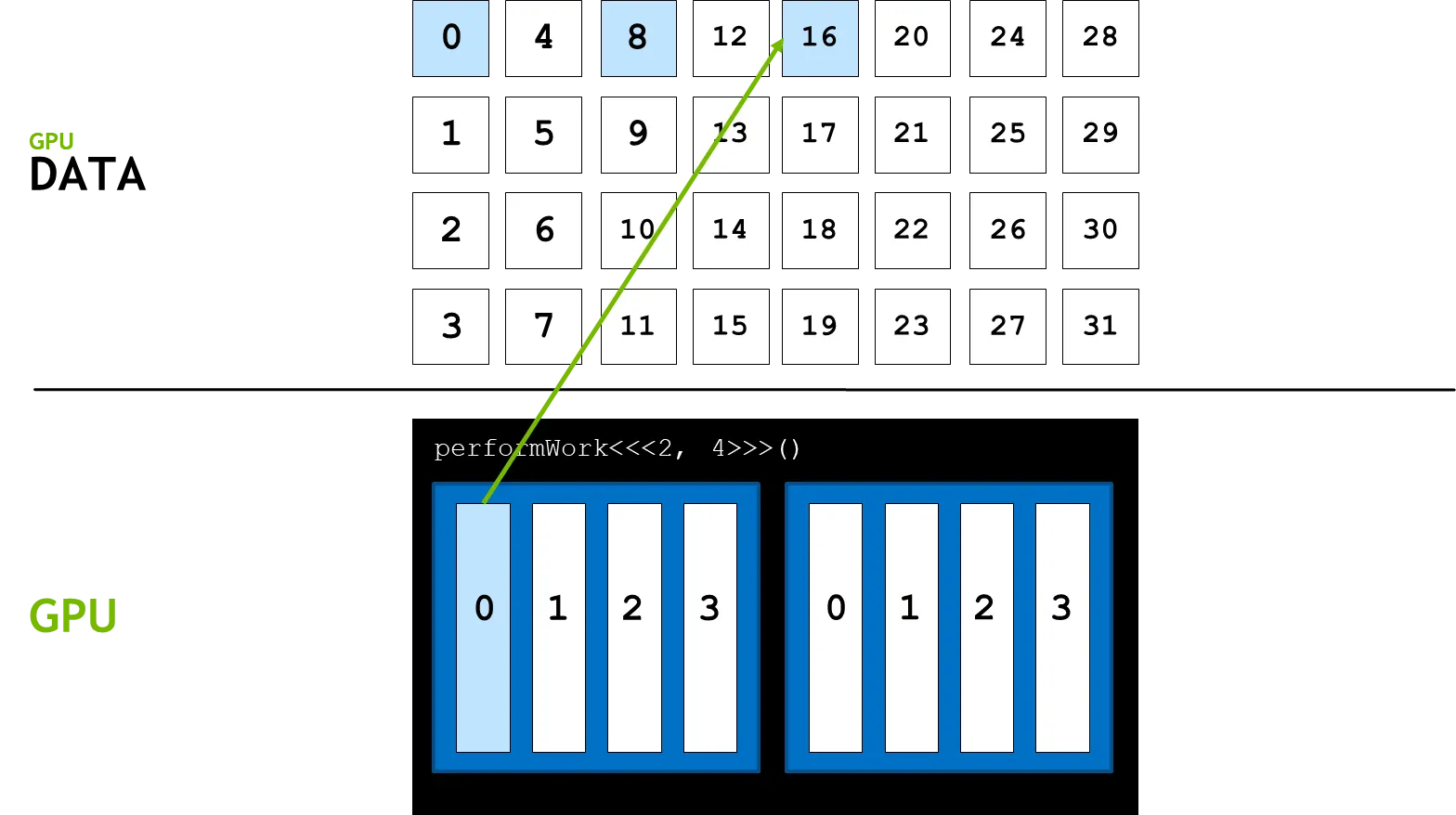
3.
그리드 당 쓰레드 수 만큼 이동하여(blockDim.x * gridDim.x) 마찬가지로 연산을 진행한다.
4.
위 과정을 데이터의 인덱스가 전체 데이터의 크기보다 커질 때 까지 반복한다.
위 방식을 적용하여 커널을 재정의 하면 아래와 같다.
__global__
void add(int n, float *x, float *y)
{
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; i += blockDim.x * gridDim.x)
{
y[i] = x[i] + y[i];
}
}
C++
복사
이러한 방식으로 전체 데이터에 대해 연산을 진행할 수 있다.
이는 입력값을 배치단위로 처리하며 각 배치는 병렬적으로 연산된다. CUDA는 여러개의 블록을 병렬적으로 한번에 사용할 수 있다. 따라서 grid-stride loops를 활용하면 커널은 쓰레드보다 훨씬 큰 데이터도 빠르게 처리할 수 있다.