
pytorch에서 가중치를 불러와 tensorflow 모델에 넣는 방식으로 코드를 작성합니다.
이를 위해 pytorch와 똑같은 구조로 tensorflow 모델를 작성한 후 kernel initializer 과정에서 pytorch 가중치를 넣고 저장하여 tensorflow 모델로 바꿉니다.
tensorflow 모델 저장 시 saved_model를 이용을 추천!
변환과정
1.
pytorch 모델과 동일하게 tensorflow 모델 작성하기
2.
pytorch 모델 불러오기
3.
tensorflow 모델 불러오면서 가중치를 pytorch 모델 가중치로 초기화하기
4.
saved_model을 이용해서 tensorflow 모델 저장하기
saved_model로 모델 저장 후엔 tensorflow lite로 바꾸는 등으로 활용할 수 있습니다.
변환 시 주의점
Convolution Kernel 순서
•
Convolution에서 pytorch의 kernel weight의 경우 [out_channels, in_channels, kernel_size(H), kernel_size(W)] 로 구성되어 있고 tensorflow는 [kernel_size(H), kernel_size(W), in_channels, out_channels] 순이다.
•
따라서 가중치를 넣어주기 전에 permute함수를 통해서 순서를 바꿔서 넣어주자
import tensorflow as tf
tf.keras.layers.Conv2D(out_planes, kernel_size=1, strides=stride, use_bias=False,
kernel_initializer=tf.initializers.Constant(
pretrained['{}.weight'.format(name)].permute(2, 3, 1, 0).numpy()))
Python
복사
padding 문제
•
대부분 pytorch에서 padding을 인자(argument)로 받을 때는 int로, tensorflow에서는 str(VALID 또는 SAME) 으로 받습니다.
•
이를 통일 하기 위해 ZeroPadding layer를 이용하여 pytorch와 똑같이 작동하도록 tensorflow 모델을 구성할 수 있습니다. 이 때, padding값이 0으로 채워지는 경우 ZeroPadding2D 를 활용할 수 있습니다.(대표적으로 Convolution 연산)
import torch.nn as nn
nn.Conv2d(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros',
device=None,
dtype=None)
Python
복사
pytorch에서 Convolution 2D
import tensorflow.keras as nn
class CustomConv2D(nn.Model):
def __init__(self,
pretrained,
name,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
*args, **kwargs):
super(CustomConv2D, self).__init__()
self.padding = None
if padding != 0:
self.padding = nn.layers.ZeroPadding2D(padding)
self.conv = nn.layers.Conv2D(
out_channels,
kernel_size=kernel_size,
strides=stride,
kernel_initializer
=tf.initializers.Constant(
pretrained['{}.weight'.format(name)]\
.permute(2, 3, 1, 0).numpy()),
bias_initializer=tf.initializers.Constant(
pretrained['{}.bias'.format(name)].numpy()
) if bias else 'zeros', use_bias=bias,
dilation_rate=dilation,
groups=groups)
def call(self, x, training=None, mask=None):
if self.padding is not None:
x = self.padding(x)
x = self.conv(x)
return x
Python
복사
Tensorflow에서 Convolution 2D
•
그러나 Maxpool의 경우 0이 아닌 -inf 를 채워넣으므로 다르게 구성하여야 합니다.
import torch.nn as nn
nn.MaxPool2d(self,
kernel_size,
stride=None,
padding=0,
dilation=1,
return_indices=False,
ceil_mode=False)
Python
복사
pytorch에서 MaxPool 2D
class CustomMaxpool2D(nn.Model):
def __init__(self, kernel, stride, padding=0):
super(CustomMaxpool2D, self).__init__()
self.padding_size = padding
self.maxpool = nn.layers.MaxPool2D(kernel, strides=stride)
def call(self, x, training=None, mask=None):
x = tf.pad(x, paddings=[[0, 0],
[self.padding_size, self.padding_size],
[self.padding_size, self.padding_size],
[0, 0]], constant_values=float("-inf"), mode="CONSTANT")
x = self.maxpool(x)
return x
Python
복사
tensorflow에서 MaxPool 2D
Conv2DTranspose layer 문제
tensorflow의 경우 그냥 Conv2DTranspose 를 활용하면 나중에 tflite로 변환 시 추가적인 operation layer가 생기며 이 경우 추후에 모바일 GPU 활용 시 연산 지원을 안해 오류가 생기게 됩니다.
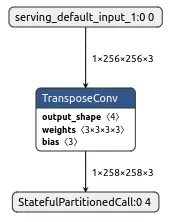
올바른 tflite 변환 파일
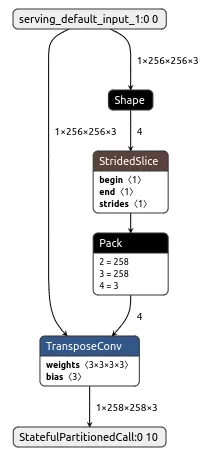
operation이 추가된 잘못된 tflite 변환 파일
따라서 Conv2DTranspose 를 활용할 경우 tf.layers.Input를 활용하여 batch size를 고정 합니다. 한마디로 흔히 사용하는(그리고 본 예제에서 계속 활용하는) subclass를 활용하지 말고 Sequential 또는 Functional API를 활용하도록 합니다. tf.layers.Input 의 위치는 Conv2DTranspose 을 포함할 수 있는 위치를 기준으로 넣도록 합니다.
참고로 subclass 방식에서 주로 활용하는 tf.keras.layers.InputLayer 를 사용하더라도 제대로 동작하지 않습니다.
import tensorflow.keras as nn
import tensorflow as tf
# 잘 동작하는 왼쪽 모델 코드
class SampleModel(nn.Model):
def __init__(self, *args, **kwargs):
super(SampleModel, self).__init__()
inputs = nn.layers.Input(shape=(256, 256, 3), batch_size=1)
outputs = nn.layers.Conv2DTranspose(3, kernel_size=3)(inputs)
self.conv1 = nn.models.Model(inputs=inputs,
outputs=outputs)
def call(self, x, training=None, mask=None):
x = self.conv1(x)
return x
# 잘 동작하지 않는 오른쪽 모델 코드
class SampleModel2(nn.Model):
def __init__(self, *args, **kwargs):
super(SampleModel2, self).__init__()
self.conv1 = nn.layers.Conv2DTranspose(3, kernel_size=3)
def call(self, x, training=None, mask=None):
x = self.conv1(x)
return x
Python
복사
BatchNormalization layer 문제
class TFBatchNormalization(nn.Model):
def __init__(self, weights, prefix,
axis=-1,
momentum=0.1,
epsilon=1e-05,
center=True,
scale=True,
**kwargs):
super(TFBatchNormalization, self).__init__()
self.bn = nn.layers.BatchNormalization(
axis=axis,
momentum=momentum,
epsilon=epsilon,
center=center,
scale=scale,
gamma_initializer=tf.keras.initializers.Constant(
weights['{}.weight'.format(prefix)].numpy()),
beta_initializer=tf.keras.initializers.Constant(
weights['{}.bias'.format(prefix)].numpy()),
moving_mean_initializer=tf.keras.initializers.Constant(
weights['{}.running_mean'.format(prefix)].numpy()),
moving_variance_initializer=tf.keras.initializers.Constant(
weights['{}.running_var'.format(prefix)].numpy()),
**kwargs)
def call(self, x, training=None, mask=None):
return self.bn(x)
JavaScript
복사
Interpolate layer 문제
"""
pytorch: F.interpolate
"""
class TFInterpolate(nn.Model):
def __init__(self, scale_factor, mode='nearest'):
super(TFInterpolate, self).__init__()
if type(scale_factor) == int:
scale_factor = (scale_factor, scale_factor)
self.layer = nn.layers.UpSampling2D(size=scale_factor, interpolation=mode)
def call(self, x, training=None, mask=None):
return self.layer(x)
JavaScript
복사
GroupNorm layer 문제
"""
pytorch: nn.GroupNorm
https://sh-tsang.medium.com/review-group-norm-gn-group-normalization-image-classification-5f7fe0f58eb6
"""
class TFGroupNorm(nn.Model):
def __init__(self, weights, prefix,
num_groups, eps=1e-5, affine=True):
super(TFGroupNorm, self).__init__()
self.G = num_groups
self.eps = eps
self.affine = affine
if self.affine:
self.gamma = tf.constant(weights[f'{prefix}.weight'].numpy())
self.beta = tf.constant(weights[f'{prefix}.bias'].numpy())
def call(self, x, training=None, mask=None):
N, C, H, W = x.shape
x = tf.reshape(x, [-1, self.G, C // self.G, H, W])
mean, var = tf.nn.moments(x, [2, 3, 4], keepdims=True)
x = (x - mean) / tf.sqrt(var + self.eps)
x = tf.reshape(x, [-1, C, H, W])
if self.affine:
return x * self.gamma + self.beta
else:
return x
JavaScript
복사
ReflectionPadding 문제
"""
pytorch: nn.ReflectionPad2d
reference: https://stackoverflow.com/questions/61993697/converting-pytorch-2d-padding-to-tensorflow-keras
"""
class TFReflectionPad2D(nn.Model):
def __init__(self, paddings=(1,1,1,1)):
super(TFReflectionPad2D, self).__init__()
if type(paddings) == int:
self.paddings = (paddings, paddings, paddings, paddings)
else:
self.paddings = paddings
def call(self, x, training=None, mask=None):
l, r, t, b = self.paddings
x = tf.pad(x, paddings=[[0,0], [t,b], [l,r], [0,0]], mode='REFLECT')
return x
JavaScript
복사
변환 예시 코드
# model_tf/model.py
import tensorflow.keras as nn
import tensorflow as tf
class TFConv(nn.Model):
def __init__(self,
pretrained,
name,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
*args, **kwargs):
super(TFConv, self).__init__()
self.padding = None
if padding != 0:
self.padding = nn.layers.ZeroPadding2D(padding)
self.conv = nn.layers.Conv2D(
out_channels, kernel_size=kernel_size, strides=stride,
kernel_initializer=tf.initializers.Constant(
pretrained['{}.weight'.format(name)].permute(2, 3, 1, 0).numpy()),
bias_initializer=tf.initializers.Constant(
pretrained['{}.bias'.format(name)].numpy())
if bias else 'zeros', use_bias=bias,
dilation_rate=dilation,
groups=groups)
def call(self, x, training=None, mask=None):
if self.padding is not None:
x = self.padding(x)
x = self.conv(x)
return x
class BasicModel(nn.Model):
def __init__(self, pretrained):
super(BasicModel, self).__init__()
self.conv = TFConv(pretrained=pretrained,
name='conv',
in_channels=3,
out_channels=3,
kernel_size=3,
stride=1,
padding=3)
def call(self, x, training=None, mask=None):
x = self.conv(x)
return x
Python
복사
# model_torch/model.py
import torch.nn as nn
class BasicModel(nn.Module):
def __init__(self):
super(BasicModel, self).__init__()
self.conv = nn.Conv2d(
in_channels=3,
out_channels=3,
kernel_size=3,
stride=1,
padding=3)
def forward(self, x):
x = self.conv(x)
return x
Python
복사
# convert_th2tf.py
import os
import torch
import tensorflow as tf
import numpy as np
from model_torch import model as thm
from model_tf import model as tfm
# Load pytorch model
TH_MODEL_PATH = 'assets/model_dump/th_model.th'
th_model = thm.BasicModel()
para_dict = torch.load(TH_MODEL_PATH)
for k in th_model.state_dict().keys():
if k in para_dict:
th_model.state_dict()[k].copy_(para_dict[k])
th_model.eval()
# Load tensorflow model and init with pytorch weight
pretrained = th_model.state_dict()
tf_model = tfm.BasicModel(pretrained=pretrained)
# Compare Pytorch model and Tensorflow model about output
## Change dimension
## because pytorch use channel-first and tensorflow use channel-last
np_input = np.ones((1, 256, 256, 3), dtype=np.float32)
th_input_tensor = torch.from_numpy(np_input).permute(0, 3, 1, 2)
tf_input_tensor = tf.convert_to_tensor(np_input)
th_output = th_model(th_input_tensor)
tf_output = tf_model(tf_input_tensor)
diff = tf_output.numpy() - th_output.detach().permute(0, 2, 3, 1).numpy()
print('diff: ', np.max(np.abs(diff)))
# Save with saved_model method
MODEL_DIR = 'saved_model/tf_model'
print('start model saving ...')
tf.saved_model.save(tf_model, MODEL_DIR)
print('... saved model complete')
## Tensorflow Lite 활용할 경우 ##
# convert to tflite
try:
tf.config.set_visible_devices([], 'GPU')
visible_devices = tf.config.get_visible_devices()
for device in visible_devices:
assert device.device_type != 'GPU'
print('Disable All GPUs')
except:
# Invalid device or cannot modify virtual devices once initialized.
pass
converter = tf.lite.TFLiteConverter.from_saved_model(MODEL_DIR)
tflite_model = converter.convert()
with open(os.path.join(ROOT_DIR, 'tflite_model.tflite'), 'wb') as f:
f.write(tflite_model)
print('tflite converting complete')
Python
복사