

SM(Streaming Multiprocessor)
NVIDIA GPU 아키텍쳐(Tesla 아키텍쳐 이후)에서 GPGPU 프로그램을 수행하는 기본단위를 SM(Streaming Multiprocessor)이라 한다.
자세한 설명



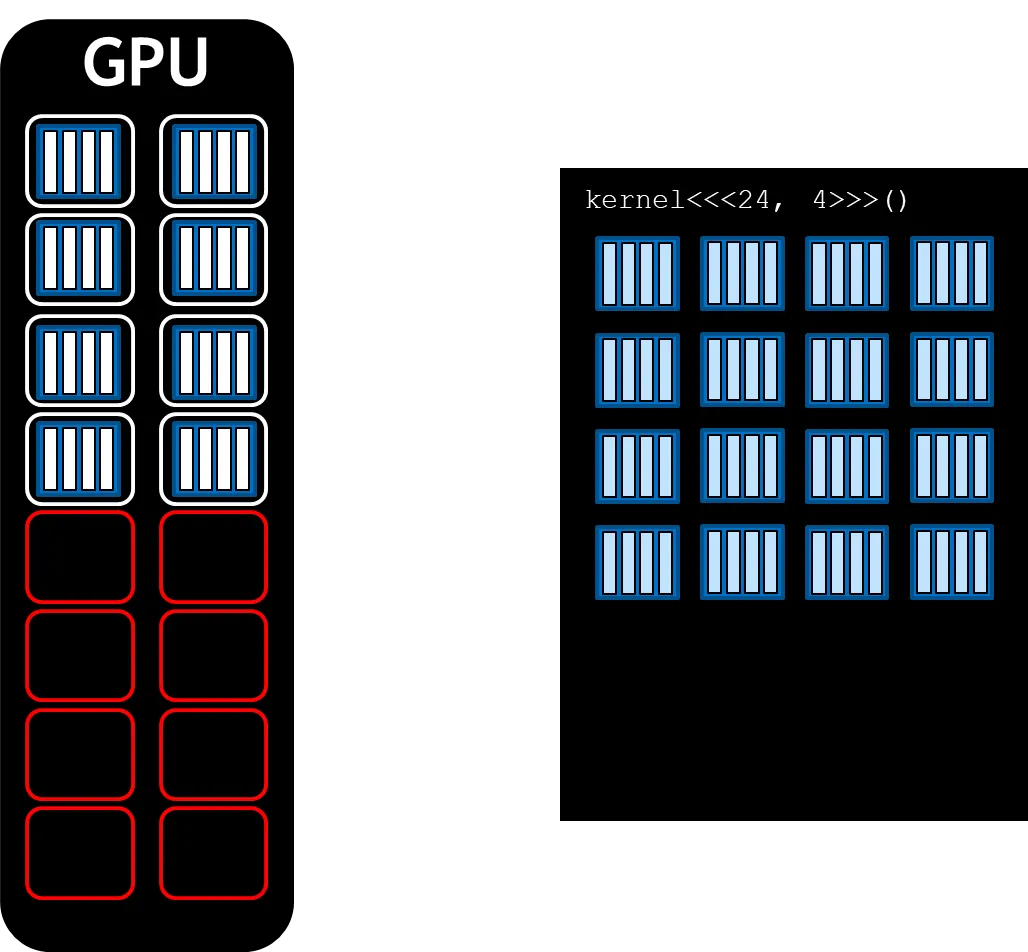
NVIDA GPU는 SM을 함수 단위(functional units)으로 가지며 쓰레드 블록은 SM에서 돌리기 위해 스케줄링 된다. SM의 개수와 요구되는 블록에 따라서 한 개 이상의 블록들이 SM에서 연산이 진행되며 이를 위해 커널이 실행되는 동안 쓰레딩 블록들이 SM에 할당된다. GPU의 병렬 연산 기능을 다양한 많이 활용하기 위해 GPU에서 주어진 여러 SM에 할당된 블록들의 숫자에 해당하는 그리드의 적합한 크기를 선택하는것이 성능에 많은 영향을 미치게 된다.
int deviceId;
int numberOfSMs;
// Get device id
cudaGetDevice(&deviceId);
// Get number of SMs
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
C++
복사
UM(Unified Memory)
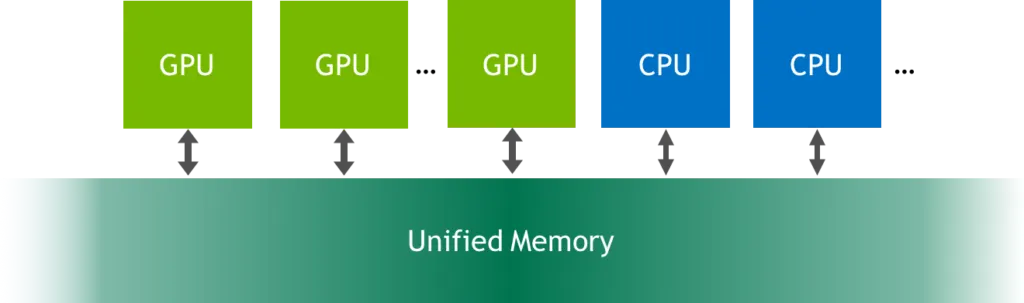
UM(Unified Memory)는 CPU 또는 GPU가 데이터를 할당하거나 접근하기 쉽게 해주는 메모리다. CPU와 GPU 모두 접근이 가능한 단일 메모리 주소 공간이며 malloc 이나 new 연산자를 cudaMallocManaged로 간단하게 대체하여 사용한다.

int main
{
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
}
C++
복사
처음 UM이 할당 되었을 때 CPU나 GPU에 초기 등록을 하진 않는다.

이후 작업에서 초기화 과정을 통해 메모리 영역에 처음 접근할 때 페이지 폴트(page fault)가 발생한다.

페이지 폴트를 통해 요구되는 메모리 쪽에 마이그레이션 과정이 시작되게 된다.
초기화과정이 아니더라도 프로세스가 등록되지 않은 변수에 접근하려고 할 때 위 마이그레이션 과정이 진행되게 된다.
void initWith(float num, float *a, int N)
{
for(int i = 0; i < N; ++i)
{
a[i] = num;
}
}
C++
복사
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
C++
복사
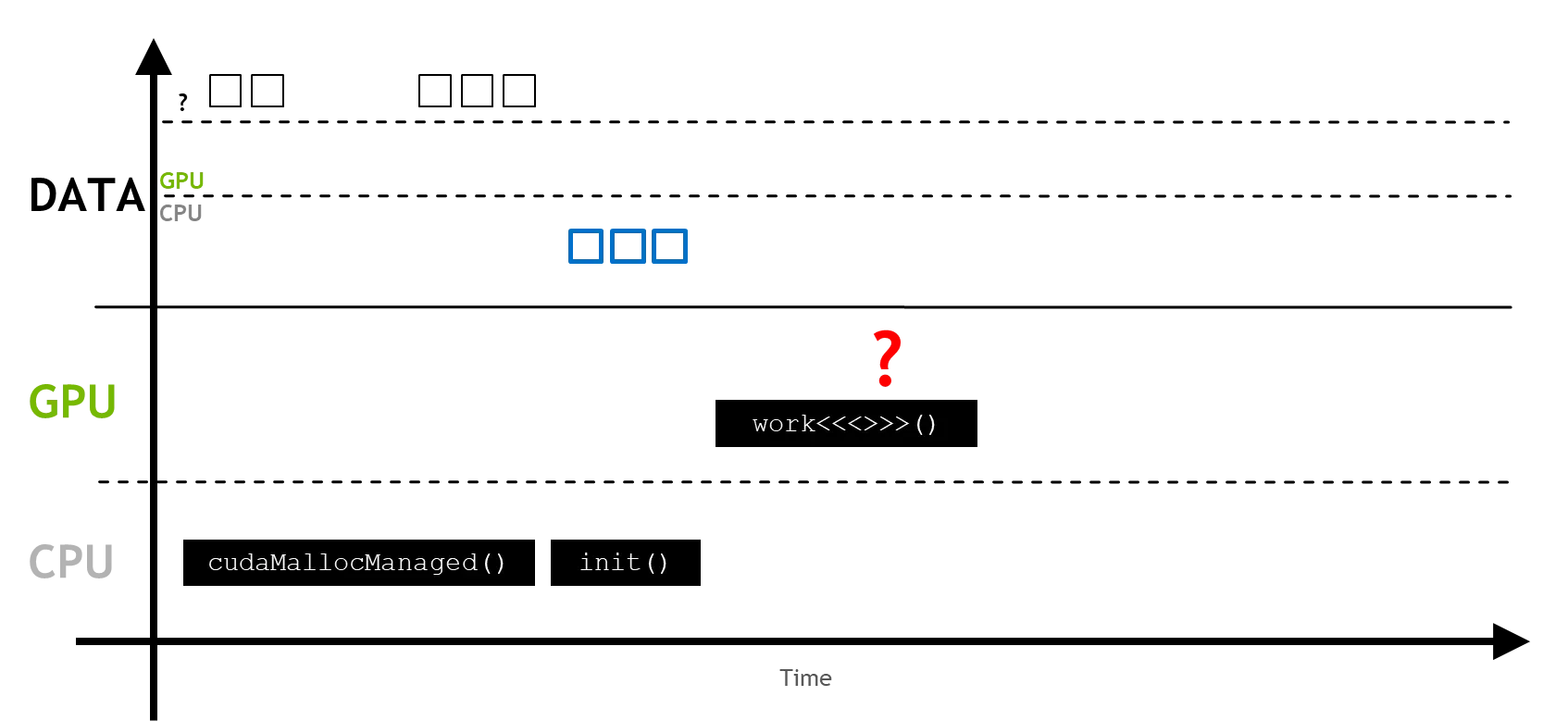

만약 메모리가 어딘가에서 등록되지 않은 변수에 접근할 것이라고 알 고 있을땐 프리페칭(prefetching)을 사용할 수 있다.

cudaMallocManaged나 cudaMemPrefetchAsync는 좋은 성능과 함께 메모리 마이그레이션 과정을 편리하고 간단하게 수행 할 수 있도록하지만 어떤 프로세서(CPU또는 GPU)에서만 연산이 진행될 때는 이를 활용하는 것 보다 각 프로세서에 직접 할당하는 것이 오버헤드를 줄일 수 있다.
예시 코드
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
void initWith(float num, float* a, int N)
{
for (int i = 0; i < N; ++i)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float* result, float* a, float* b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float* vector, int N)
{
for (int i = 0; i < N; i++)
{
if (vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2 << 24;
size_t size = N * sizeof(float);
float* a;
float* b;
float* c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
addVectorsInto << <numberOfBlocks, threadsPerBlock >> > (c, a, b, N);
addVectorsErr = cudaGetLastError();
if (addVectorsErr != cudaSuccess)
printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if (asyncErr != cudaSuccess)
printf("Error: %s\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
C++
복사