
Introduction
여느 3D 관련 분야들과 같이 옷을 입은 사람에 대한 학습 문제에서 가장 큰 이슈 중 하나는 데이터가 부족하다는 것이다. 게다가 현재 있는 데이터들도 다양한 포즈나, 외형, 그리고 옷의 복잡한 모양을 포함하지 않는다. 본 연구에서는 소셜미디어에 공유된 수백만의 댄스 동영상을 활용하여 옷입은 사람의 3D를 단일 카메라로 부터 depth와 surface normals의 형태를 이용하여 높은 정확도로 데이터를 구성하는 새로운 방법을 제시하였다. 이 댄스 동영상의 특징은 아래와 같다.
1.
각 각의 비디오는 한 사람의 다양한 자세를 시퀀스 형태로 구성되어 있다.
2.
3D GT 데이터는 포함하지 않는다.
최근 학습 기반의 깊이 추정 모듈(depth estimators)를 많이 사용하고 있다. 그러나 깊이 추정만 활용하면 전체 신(scene)은 잘 추정하지만 복잡한 옷의 주름이나 얼굴의 특징 등의 세밀한 부분을 표현하는데는 부족하다. 반면에 surface normals는 텍스쳐와 주름과 같은 세세한 시각적 특징을 잘 표현할 수 있다. 이에 따라 본 연구에서는 깊이정보와 surface normal를 모두 활용하는 방식을 제안하였다.
또한 end-to-end trainable한 방법으로써 RGB 이미지와 이에 맞는 human foreground 그리고 사람의 UV좌표를 입력값으로 가지고 이를 통해 높은 정확도의 깊이값(depth)을 출력값으로 가진다. 간단하게 정리하면 아래 두 가지 과정을 활용하였다.
•
먼저 HDNet이란 이름의 네트워크를 설계하였으며 이를 통해 이미지 좌표와 UV 사이의 공간적 관계를 학습하여 최종적으로 이미지에서 surface normal을 출력하는 네트워크를 생성하였다.
•
두 번째로 서로 다른 프레임의 비디오를 비교한다. 이를 위해 HDNet을 샴(Siamese) 네트워크 디자인을 활용하였으며 한 쌍의 HDNet을 이용하여 self-consistency를 측정하여 적용하였다.

Method
Self-supervised Human Depths from Videos
는 옷을 입은 사람의 이미지이고 이를 매개변수로 하며 각 픽셀 좌표값인 을 통해 깊이값 를 구하는 함수를 라 하였다. 는 UV 좌표를 이용하여 재 구성한(reconstruction) 좌표이며 는 카메라 내부 파라미터(camera intrinsic parameter)이고 는 UV좌표 와 일치하는 이미지 좌표를, 그리고 는 시간값(순서)울 의미한다.
즉, 위 수식을 정리하면 먼저 , 좌표에 카메라 내부파라미터 행렬을 곱하면 3차원 좌표(eye coordinate 입장에서의 좌표계)계로 변환되고 여기에 축 방향벡터를 곱한 것이 UV값이 된다는 것이다. 이는 UV라는것이 빛이 반사되는 방향, 즉 퍼지는 쪽 법선 벡터라는 것을 표현한 식이 되겠다. 그 뒤는 는 를 통해 구해짐을 의미하며 이는 함수 는 UV의 surface coordinate로이미지의 좌표값 을 구하는 함수라는 것이다.
는 warping function으로 본 연구에서는 3D 파츠 기반(part based)으로 설계되었으며 는 의 바디 파츠를 말한다. 즉 는 개의 바디 파츠 단위로 UV좌표를 옮기는 함수이다. 본 연구에서는 Special Euclidean Transform(SE3)를 사용하여 함수 를 정의하였으며 식은 아래와 같다.
즉 표현하면 함수 는 회전 및 평행이동 변환을 통해 어떤 좌표를 파츠 단위로 다른 좌표로 옮겨주는 함수이며 실제 번째 3D좌표와 함수 와 번째 좌표를 이용하여 구한 좌표와의 거리가 최소화가 되도록 손실함수를 설계하였다.
정리된 손실함수는 아래와 같다.
Joint Learning of Surface Normal and Depth
는 깊이추론 모듈(depth estimates)로 부터 구해진 깊이정보(depth) 3D 좌표를 이용하여 구한 unit surface normal vector고 는 이미지로 부터 바로 추론된 unit surface normal vector이다. 은 위 수식 처럼 카메라 좌표계 시스템(camera coordinate system) 축 기준으로 직각성분으로 구한다.
이러한 방식으로 구해진 깊이추론 모듈로 부터 나온 surface normal값 와 이미지로 부터 구해진 의 코싸인유사도를 통해 손실값 를 구하며 의 역행렬을 곱했으므로 각도 값으로 구해진다.
Network Design
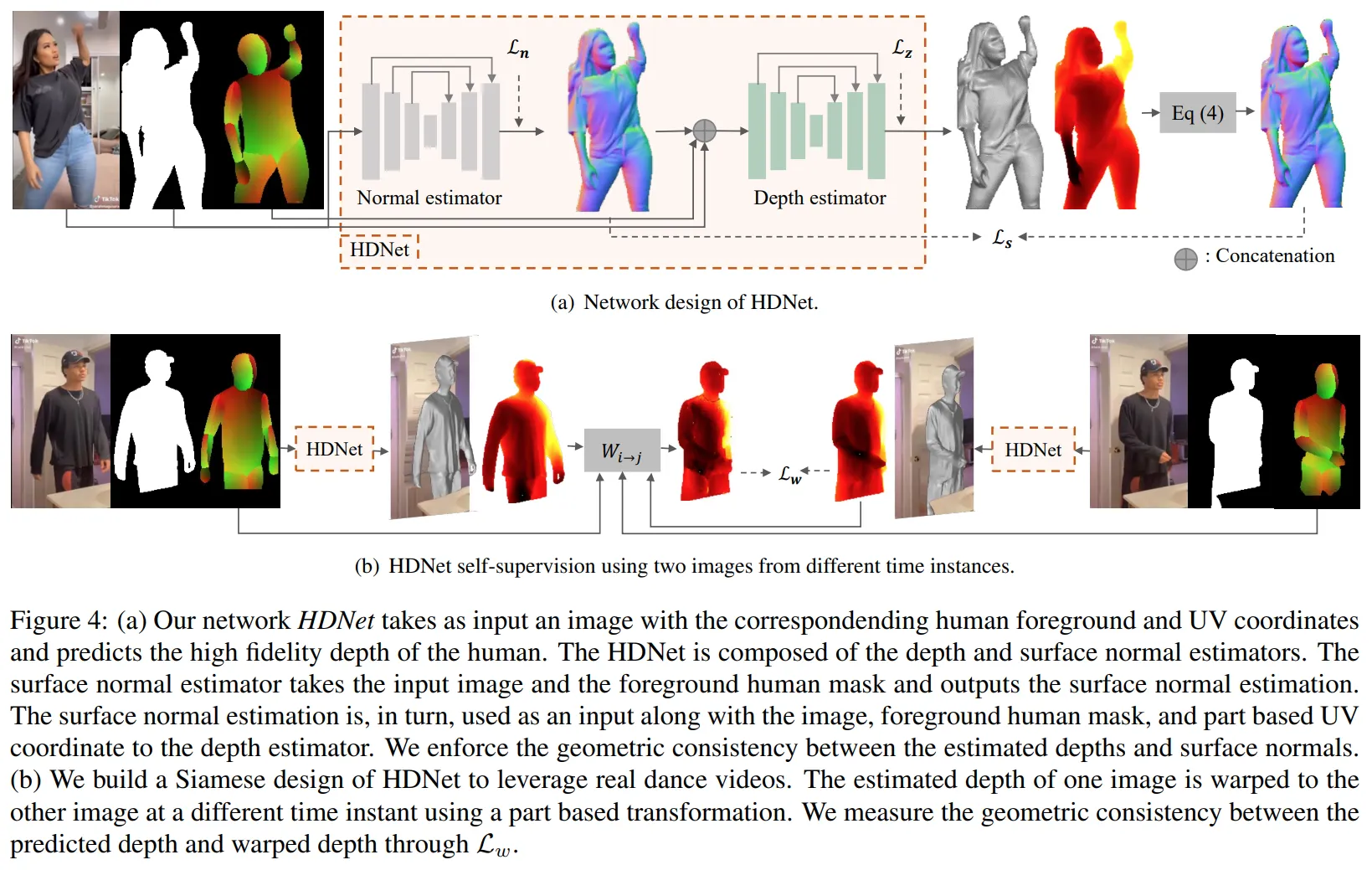
와 는 위에서 구한 self-consistency losses이며 나머지 와 은 3D 스캔 데이터로 부터 만들어진 3D GT 데이터셋을 통해 구한다. 는 3D 스캔데이터 이며 와 는 이를 통해 구해진 GT depth와 surface normal이다.
Network Design and Detail
본 연구에서는 HDNet(Human Depth Neural Networks)라는 실제 비디오와 스캔데이터를 활용하는 네트워크를 제안하였다. HDNet은 surface normal estimators와 depth estimators 로 두 개의 estimator로 구성되어있다. surface normal estimators는 RGB영상과 휴먼 마스크를 입력으로 받아 surface normal을 출력한다. 그리고 depth estimators는 RGB이미지, 휴먼 마스크, 그리고 UV 좌표값을 받아 depth값을 출력한다.
또한 시간축의 데이터를 활용하기 위해 HRNet을 이용한 샴 네트워크를 활용하여 구성하여 같은 비디오에서 다른 프레임 데이터를 처리하도록 하였다.
.png&blockId=a7e5938c-4db9-45cc-9f7d-a714020d6350)
두 개의 estimator는 stacked hourglasses 네트워크를 백본으로 활용하여 설계하였다. 이미지와 휴먼 마스크(foreground mask)는 256x256 이미지로 부터 crop하여 만들어졌으며 는 Densepose로 부터 구해진 UV 맵을 inverse하여 구하도록 설계하였다.
기타 정보
Experiments
본 연구에서는 두 개의 데이터셋을 활용하였다.
Training Datasets
•
두 가지의 데이터셋 활용
1.
3D 스캔모델(RenderPeople)로 부터 구해진 340개의 subject으로 구성도니 3D GT 데이터셋
2.
본 연구에서 구축한 3D GT가 없는 TikTok 데이터셋
•
16.5mm의 초점거리를 가진 6m직경의 100개의 카메라로 부터 랜덤하게 샘플링된 데이터를 렌더링 하여 만든 3D 스캔 데이터
•
RenderPeople과 TikTok 데이터에서 각각 34,000개의 데이터와 100,000개의 이미지가 훈련을 위해 사용되었다.
Evaluation Datasets
퍼포먼스 테스트를 위해 3가지 데이터셋을 활용
•
Training dataset of Tang et al
•
RenderPeople dataset
•
Vlasic et al. dataset
추가
•
데이터 셋을 만드는 과정이 SMPL을 만드는 과정과 유사했다. 특히 함수 의 매개변수를 구하는 과정은 SMPL에서 각도를 주고 deformation을 구하는 것과 많이 닮았다. 차이점이라면 SMPL에서는 각도를 주고(R과 T를 준 것과 같음) 변환을 했을 때 이동되는 정도를 구했다면 본 연구에서는 옮겨지는 정도를 통해 각도를 구하는 과정이란 차이가 있었다. 특히 파츠 단위로 분해하여 움직이는 개념이 굉장히 많이 유사했다.