요약
야외 이미지를 위한 카메라파라미터가 부족하기 때문에 현재 존재하는 3D Human pose and shape (HPS) 추론 분야는 몇가지 간단한 가정을 한다. 첫째로 weak-perspective projection, 둘째로 큰 크기(일반적으로 5000px)의 고정된 초점거리(focal length)로 하며, 마지막으로 카메라의 회전행렬을 영행렬로 둔다. 이러한 가정으로 인해 3D shape과 pose를 추정할 때 정확도가 떨어지게 된다. 이를 해결하기 위해 본 연구에선 SPEC이라 이름지은 단일 이미지로 부터 perspective camera를 추정하고 이를 통해 사람의 3차원정보를 정확하게 추정할 수 있도록 했다. 먼저 본 연구에서는 주어진 이미지로 부터 fov(field of view, 화각), 카메라의 pith와 roll을 추정하는 인공신경망을 훈련시켰다. 여기서 이전 연구보다 카메라의 캘리브레이션 성능을 높이기 위한 새로운 손실함수를 적용하였다. 그 후 다른 네트워크로 부터 나온 image feature와 카메라 캘리브레이션 출력값과 합하여 활용함으로써 3차원 shape과 pose를 추론하는데 활용하였다. 해당 부분은 뒤에 네트워크 아키텍쳐를 설명할 떄 자세히 설명한다.
SPEC은 3DPW 데이터셋에서 기존 모델들 보다 좋은 성능을 보였을 뿐 만 아니라 카메라의 뷰와 다양한 초점거리를 포함한 난이도 높은 데이터셋에서도 좋은 성능을 보였다. 특히, 본 연구에선 새로운 실제같은 가상데이터셋인 SPEC-SYN과 GT 3D 사람과 야외이미지로 이루어진 데이터셋 SPEC-MTP를 구축하였다. 코드와 데이터셋은 연구목적으로 활용될 수 있게 공개되어 있다.

기존 대부분의 연구는 아래 세가지 가정을 기반으로 모델을 설계한다.
1. weak perspective projection 또는 orthographic projection을 활용 (→ 원근감이 거의 없음을 의미함)
2. 큰 크기로 고정된 초점거리
3. 항등행렬과 영행렬로 구성한 카메라 회전행렬
본 가정이 적용되려면 카메라의 축과 사람의 축이 수직이어야 하고 카메라로 부터 충분히 멀어야 한다. 그러나 실제 상황에선 이러한 가정이 적용되지 않는 경우가 많으며(셀카 등) 이는 정확도의 감소로 이어지게 된다.
본 연구는 이러한 부분을 지적하며 위 가정을 하지 않도록 카메라의 초점거리와 회전행렬을 구하는 방식으로 문제를 해결하려고 시도한 연구다.
관련연구
캘리브레이션 된 카메라에서의 3D HPS
단일 이미지 기반 HPS
단일이미지 카메라 캘리브레이션
메소드
사전지식
단일이미지 기반 카메라 캘리브레이션
데이터셋
데이터셋은 Pano360 datasets, SPEC-SYN, SPEC-MTP, 3DPW, COCO, MPI-INF-3DHP, Human3.6M 데이터셋등을 사용하였다.
평가 매트릭스
기존 연구는 MPJPE, PA-MPJPE, PVE를 평가지표로 사용하며 이는 카메라에 대한 정보가 반영이 될 필요가 없는 평가지표이다. 따라서 본 연구에서는 World가 적용된 형태인 W-MPJPE와 W-PVE를 평가지표로 활용하였다. 본 연구에서 나온 출력값은 로 계산하였다. 기존 SOTA 메소드의 경우는 와 로 나눠 성능평가를 진행했으며 는 CamCalib를 통해서 구하여 활용했으며 모든 메소드에 대해 이미 알려진 카메라 회전값은 활용하지 않았다.
자세한 설정값
CamCalib 백본으로 ResNet-50을 활용하고 pitch , roll , fov 를 각각 FC Layer로 header를 만들어 출력하였다. 는 Softargmax-biased-를 적용하였고 , 엔 Softargmax-를 적용하였다. 모델은 다양한 크기의 이미지를 활용하여 학습하였으며 총 30 에포크로 적용하였다.
SPEC 원본 HMR구조와 같이 ResNet-50을 백본으로 활용하였다. 본 연구는 psuedo-ground-truth 3D 데이터를 훈련데이터로 활용하였기 때문에 HMR의 discriminator는 사용하지 않았다. 의 학습률로 아담 옵티마이저를 사용하였고 초기 150번째 에포크까진 COCO 데이터셋과 SPEC-SYN 데이터셋을 활용하였고 이후 MPI-INF-3DHP와 Human3.6M 데이터셋을 적용하여 총 175 에포크를 진행하여 총 4~5일 정도의 시간이 소요되었다.
CamCalib와 SPEC은 따로 학습을 진행하였다. 이는 양 데이터를 포함한 야외데이터셋이 부족하기 때문이며 SPEC-MTP 데이터의 경우 두 조건을 충족하나 데이터가 적어 평가데이터로만 활용하였다.
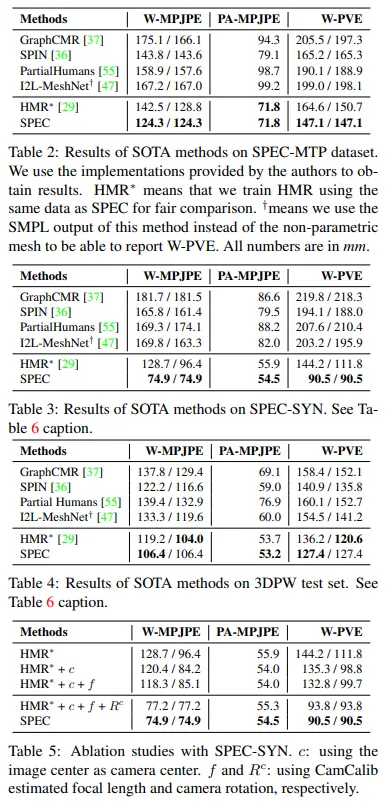
결과
개인 생각: 전체적으로 봤을때 CamCalib의 경우 지평선 라인이 보이지 않는 경우 잘 안나오는것으로 보임. 이는 네트워크 문제보다는 이미지에서 가지고 있는 정보를 네트워크가 잘 녹여내지 못하지 않았나란 생각이 듬.
또한 회전매트릭과 fov를 이미지 feature와 합치는게 적절했는지도 의문임. 특히 fov의 경우 angle이며 연속공간이 아님. 합치는 feature값들이 위상적으로 동형인 공간이 아닌데 이러한 부분이 성능 저하를 일으킨게 아닌가란 판단이 듬.
추가로 이미지의 단서를 통해서 카메라의 기하적 특성을 뽑아낸 시도는 훌륭했으나 SMPL 바디의 회전값은 crop된 이미지를 활용하여 기존 방식과 크게 달라지지 않아 이러한 부분을 추가 연구로 하면 좋지 않을까란 생각이 들었음. (말이 되는진 모르겠는데 CamCalib와 백본 피쳐를 공유하여 바디 회전값을 출력하는 헤더를 같이 둠)