손과 손 사이의 상호적인 동작에 대해 분석하는 것은 사람의 행동을 이해하는데 중요한 과정이다. 그러나 대부분의 3D hand pose estimation 분야에서는 두 개가 아닌 한 개의 손을 추정하는데 집중되어 있다. 이에 따라 본 연구에서는 (1) InterHand2.6M이라는 데이터셋을 소개하고 (2) InterNet이라고 하는 단일 RGB이미지로 부터 상호작용하는 3차원 손을 추정하기 위한 baseline network를 보여준다. InterHand2.6M 데이터셋은 2.6M 개의 라벨링된 여러 시나리오로 부터 나온 다양한 포즈로 구성된 단일 프레임의 상호작용하는 손 데이터로 구성되어 있다. 또한 InterNet의 경우 동시에 3D 단일 프레임으로 상호작용하는 hand pose estimation을 수행한다.
InterHand2.6M 데이터셋은 RGB-based인 3D Hand 데이터셋으로써 한 사람에 대해 한개 또는 상호작용하고 있는 두 손으로 구성된 데이터셋이다. 본 데이터의 경우 정확하게 캘리브레이션 된 다중 카메라 스튜디오(multi-view studio)을 이용하여 구축하였으며 데이터 구축을 위해 80~140개의 고화질 카메라를 활용하였다. 3D keypoint 좌표 어노테이션을 위해 반자동화 접근방식을 활용하였다.
InterNet의 경우 동시에 3차원의 단일 그리고 상호작용하는 손을 단일 이미지로 부터 추정하는 모델임. InterNet은 2.5D 의 오른손 왼손 포즈를 추정하는데 이는 손의 x좌표와 y좌표, 그리고 왼손으로 부터 오른손 까지의 depth 정보에 해당하는 z좌표를 의미한다. 2.5D를 3D로 리프팅 하기 위해 RootNet을 활용하여 absolute depth를 구했는데 RGB 이미지로 부터 이를 구하는 것은 높은 모호성(ambiguous)를 내포한다(2.5D라는건 RootNet을 사용하기 전 완전한 3D가 아닌 상대적인 3D좌표로 이뤄진 차원을 의미하는 듯 하다). 이를 해결하기 위해 InterNet은 입력 이미지에서 상호 작용하는 손의 모양을 활용하여 오른손과 왼손의 상대적인 깊이 정보를 예측하도록 디자인 되었다. 이러한 상대적인 깊이 정보는 이미지에 양손이 모두 나타나는 경우에 RootNet을 대신하여 활용되었다.
InterHand2.6M
80~140개의 카메라로 구성된 multi-camera studio에서 30~90 fps로 촬영하였으며 균일한 음영을 반영하기 위해서 350~450개의 LED point light를 활용하여 구축하였다. 카메라는 4096 X 2668 해상도로 촬영되었다. multi-view system의 경우 3D calibration target 을 활용하여 픽셀 기준 root mean squre error 기준 오차범위 0.42에서 0.48로 구성하였다.

19명의 남성, 7명의 여성으로 부터 36가지의 데이터 종류를 구성하였다. hand sequences를 측정하기 위해 두 가지 방식을 사용하였다.
•
Peak Pose(PP)는 기본 손 자세로 부터 다양한 사인 제스처를 포함하는 미리 정의된 손 동작으로 움직이고 다시 원래 기본 손 자세로 돌아오기 까지의 전환을 말한다. 본 연구에서는 가각 오른손과 왼손으로 구성된 40개의 미리 정의된 손 자세와 13애의 상호작용하는 손으로 구성하였다. 중립자세에서 손은 사람의 가슴 앞에, 손가락은 붙 지 않은 상태로 되어있다.
•
Range Of Motion(ROM)은 대화식의 제스쳐를 표현한다. 오른손과 왼손 중 하나만 이용ㅇ하는 15종의 대화형 제스쳐와 17개의 양손을 활용하는 제스쳐로 구성하였다고 한다.
본 연구에서는 특정 어플리케이션 때문이 아닌 일반적인 동작을 담기 위해 이러한 방식으로 데이터를 구성했다고 한다.
Annotation
손의 keypoint를 어노테이션하기 위해 본 연구에서는 42개의 독립적인 포인트를 사용하였다(각 손당 21개 x 양손 = 42개). 각각의 손 끝과 3개의 관절에 대한 회전정보를 어노테이션 하였다. 즉 또한 손 하나당 20개의 키보인트와 손목의 회전값이 어노테이션 되었다.
회전값을 어노테이션 하는것은 어려운 문제인데 이는 관절의 중심은 회전값은 피부에 의해 가려지기 때문이다(회전값은 겉이 아닌 내부 중심에서의 값을 의미하므로). 또한 손가락이 다른 손가락에 의해 가려질 땐 더욱 풀기 어려운 문제가 된다. 때문에 본 연구에서는 어노테이션 작업자가 6개의 이미지를 동시에 볼 수 있는 어노테이션 툴을 개발하였다. 이 6개의 이미지는 동시에 다른 각도로 부터 캡쳐되므로써 작업자들이 사실상 3차원 공간을 어노테이션 할 수 있도록 한다.
어노테이션 툴을 효율적으로 구성할 지라도 이미지의 양이 워낙 많기 때문에 높은 인력 투입이 필요하다. 이에 따라 본 연구는 두 단계로 구성된 절차를 설계하였다.
첫 번째 단계에서 작업자가 어노테이션 작업을 수동으로 진행한다. 위에 언급한 자체 개발한 툴을 활용하며 2차원 키포인트를 찍는 방식인데 한 프레임당 80개 이상의 view가 있으므로 이를 triangulated(멀티뷰 카메라에서 3차원 좌표를 추정하는 방식을 뜻함) 하여 3차원 좌표를 추정한다. 최종적으로 첫 번째 단계에서 총 698,922장의 라벨링된 데이터를 만들어 낸다.
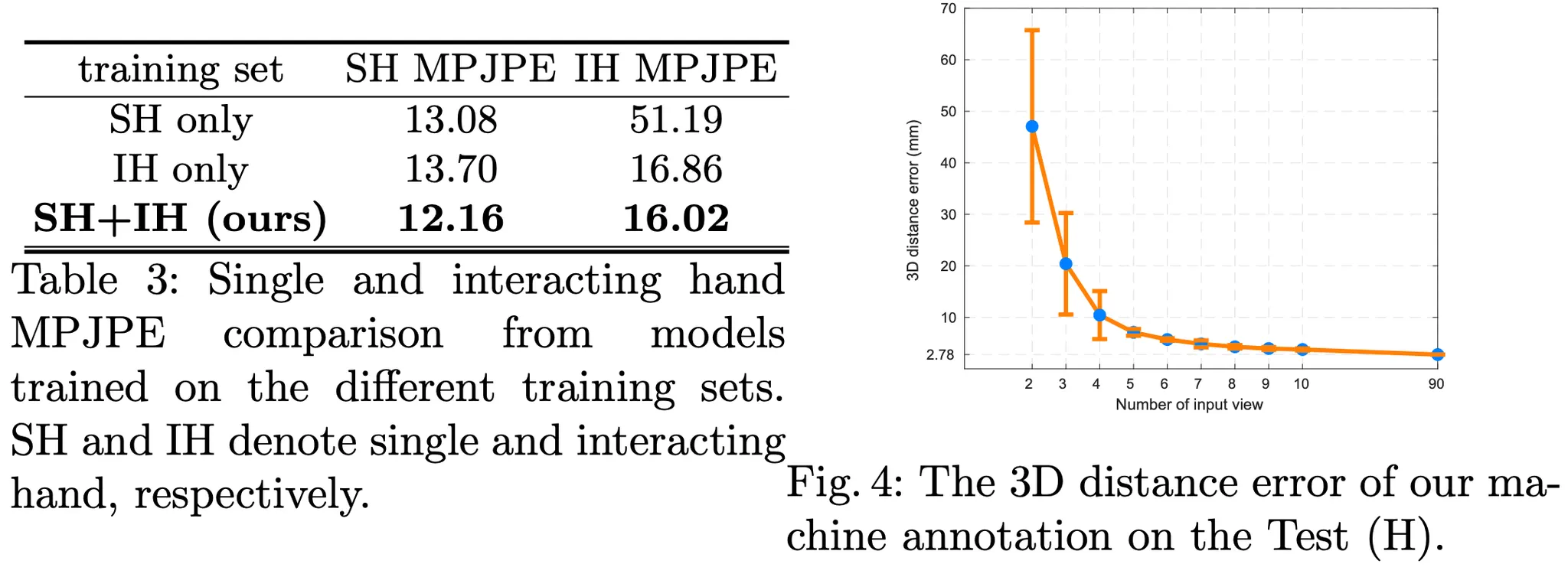
두 번째 단계에서는 자동화된 어노테이터를 이용한다. 이를 위해 가장 성능이 좋은 2D Keypoint detector를 선정 후 앞에 작업한 데이터를 이용해 학습한 모델을 사용하였다. 연산 효율화를 위해 backbone은 EfficientNet을 사용하였다. detector는 첫번째 단계에서 라벨링 되지 않은 이미지를 대상으로 하였으며 3차원 좌표를 얻기 위한 triangulation 알고리즘은 RANSAC을 활용하였다. InterHand2.6M 데이터셋은 많은 숫자의 높은 해상도의 카메라를 이용했기 때문에 머신 기반의 자동화 어노테이션 detector는 높은 정확도를 보였다. 해당 모델은 자체 평가데이터에서 2.78mm의 오차를 보였다. 최종적으로 본 데이터셋은 첫번째 단계에서 만들어진 데이터와 두번째 단계에서 만든 데이터를 합쳐서 구성하였다. 보통 이미지에서 손이 차지하는 영역은 작기 때문에 성능이 떨어지는데 본 데이터셋에 활용된 이미지는 고해상도이기 때문에 detector가 잘 동작했다고 언급한다.
Dataset release
최종적으로 이미지를 다운사이즈 하여 512 x 332 의 해상도에 5fps로 구성하여 데이터셋을 릴리즈 하였다. 다운사이즈 과정에서 지문정보를 제거하였다. 어노테이션 파일은 카메라종류, 동작정보 인덱스, 카메라 인덱스, 바운딩박스, handedness(왼손, 오른손, 양손 등의 플래그를 뜻하는 듯 함), 카메라 파라미터, 그리고 3차원 조인트 좌표를 포함하고 있다.
InterNet
본 연구에서 샘플 모델로 공개한 InterNet은 단일 RGB이미지를 입력값으로 하는 모델로 끝에 fully-connected layer를 없앤 ResNet을 백본으로 활용하여 이미지 피쳐(feature)를 뽑는다. 이미지는 손 영역으로 cropped된 이미지이다. 본 모델은 이 F로 부터 InterNet은 handedness(왼손, 오른손, 양손 구분), 2.5D의 오른손 왼손 포즈, 그리고 오른손 기준으로 상대적인 왼손의 깊이(depth) 정보를 동시에 추정한다. 2.5D의 hand pose estimation에 대해서는 따로 손 크기에 대한 정규화를 진행하진 않았다.

Handedness estimation
어떤 손이 이미지에 포함되어 있는지 확인하기 위해 왼손과 오른손의 존재 여부를 확률(히트맵)으로 표현하였다. h
이를 위해 2개의 fully-connected layer를 활용하였고 이미지 피쳐 를 입력으로 받아 확률 를 구한다. fully-connected layer의 hidden activation size는 512로 설정하였고 마지막 레이어를 제외하고는 ReLU를 활성화함수로 사용하였다. 마지막 레이어는 확률값으로 출력하기 위해 sigmoid 함수를 이용하였다.
2.5D right and left hand pose estimation
2.5D의 오른손 왼손 포즈추정을 위해 각각 upsampler를 활용하였다.
각 upsampler는 3개의 deconvolution layer와 1개의 convolution layer로 구성하였고 각 deconvolution layer에는 batch normalization layer와 ReLU 함수를 추가하여 배로 upsample 한다. upsampler는 이미지 피쳐맵 를 입력을 받아 와 로 표현되는 왼손과 오른손 조인트에 대한 3차원 가우시안 히트맵을 출력한다.
에서 x축과 y축은 이미지 공간이고 z는 상대적인 깊이 공간을 지칭한다. 2차원 피쳐맵으로 부터 3차원 가우시안 히트맵을 구하기 위해 upsampler에 reshape function ()을 이용하였다. 3차원 가우시안 히트맵의 voxel은 hand joint j의 위치에 대한 우도(likelihood)를 의미한다.
Right hand-relative left hand depth estimation
각 손의 깊이정보는 손의 root joint로 정의된다. 본 연구에서는 마지막 레이어를 제외하고 2개의 FCN과 ReLU 함수를 사용하였고 FCN의 hidden activation size는 512이다. 그 후, 여기서 부터 나온 피쳐맵 을 1D heatmap 로 출력한다. 그리고 나서 이 에 soft-argmax 함수를 적용해서 상대 깊이값인 를 출력한다. 본 연구는 soft-argmax operation에 의한 1D heatmap을 추정하는것이 바로 깊이값을 추정하는것에 비해서 더 정확한 결과를 보인다는것을 확인했다.
Final 3D interacting hand pose
최종 아웃풋인 3d hand pose 과 는 아래와 같은 식에 의해서 출력된다.
는 camera back-projection을 의미하고 는 2D crop이나 resize 등의 inverse affine transformation을 의미한다(일종의 후처리?). 는 깊이값으로 와 의 형태이며 아래와 같이 정의 된다.
본 연구에서는 RootNet을 활용해서 해당 값들을 얻었다.
Loss functions
InterNet을 학습하기 위해 아래 3개의 loss function을 활용하였다.
Handedness loss
왼손 또는 오른손이 존재하는지에 대한 loss function으로 binary cross-entropy loss function을 사용하였다. 는 손의 존재에 관한 이진값이다. 해석하면 있을때는 있을 확률을, 없을 때는 있을 확률의 역이 최소화 되도록 설계되었다.
2.5D hand pose loss
*는 GT값이다. 만약에 오른손 또는 왼손이 존재하지 않을 때는 Loss값을 0으로 하였다. GT에 해당하는 3D Gaussian heatmap은 아래 수식을 통해 계산된다.
, , 은 로 부터 얻어진 번째 joint 좌표이다.
Right hand-relative left hand depth loss
L1 loss를 사용하였으며 왼손이 오른손으로 부터 떨어진 거리에 관한 부분을 반영하도록 설계되었다.
Implementation details
본 연구에서 백본은 ImageNet 데이터로 사전학습된 ResNet-50을 사용하였고 나머지 부분은 의 가우시안 분포를 활용하여 초기화 하였다. optimizer는 mini-bath size 64로 adam을 활용하였다.
input size 는 256x256, heatmap size는 , 로 세팅하였다.
augmentation은 translation , scaling , rotation , horizontal flip, color jittering 을 적용하였다.
학습률(learning rate)은 초기에는 로 시작해서 15epoch부터 17epoch에 거쳐 10배씩 줄였다. 본 모델은 총 20 epoch를 진행하였으며 NVIDIA TitanV GPU로 interHand2.6M 데이터를 사용하여 48시간이 걸렸다. 본 모델은 53 fps의 속도성능을 가진다.
Experiment
Dataset and evalutation metric
STB STB는 6개의 스테레오 카메라를 이용한 한명에 대한 여러 배경과 다양한 포즈의 시퀀스를 가진 데이터이다. 평가를 위해 end point error(EPE)를 사용하며 이는 3D hand pose의 root joint에 대한 유클리디안 거리이다.
RHP RHP는 많은수의 합성 이미지로 구성되어 있으며 20개의 여러 주제에 관해 39개의 액션을 합성 하기 위해 3D Human model을 활용하였다. 마찬가지로 EPE를 활용하여 평가한다.
InterHand2.6M InterHand2.6M은 본 연구에서 구축한 데티터셋이다. 3개의 매트릭스를 이용하여 평가하는데 첫째로 손 존재 여부 추정(handedness estimation)에 대한 AP를 측정한다. 둘째로 3D joint 위치에 관한 오차를 측정하기 위해 유클리디안 거리로 정의된 MPJPE를 활용한다. 마지막으로 root에 상대적인 거리에 관한 오차를 측정한다.(MRRPE).