

일반적인 CUDA 프로그래밍의 패턴은 아래 세 순서를 따른다.
1.
데이터를 CPU(host)에서 GPU(device)로 복사한다.
2.
GPU(device)에서 커널을 수행한다.
3.
커널의 실행결과를 다시 CPU(host)로 복사한다.
위 3가지 단계를 통해 연산을 처리할 때, GPU 프로세서는 1번과 3번단계를 수행하는 동안 대기하고 2번 단계가 되어야 연산을 처리하게 된다. 이를 개선하기 위해 GPU에서 2번단계를 진행하는 동시에 데이터를 전송하는 1번, 3번 단계를 진행하게 되면 전체 효율을 높일 수 있다.
CUDA Streams
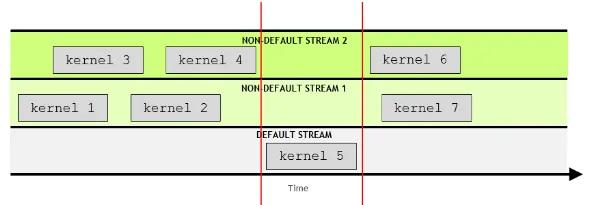
스트림(Streams)은 설정된 순으로 실행되는 명령어 순서를 말한다. CUDA 어플리케이션에선 커널실행 뿐 만 아니라 메모리 전송(memory transfers) 또한 CUDA 스트림에서 일어난다. 스트림에서의 작업(operation)은 CPU(host)와 항상 비동기적으로 실행된다. 또한 동일한 스트림에서 작업들은 정해진 순서에 의해 진행되지만 서로 다른 스트림에선 실행순서에 제한이 없다.
스트림을 명시하지 않은 상황에서 사용되는 스트림을 디폴트스트림(default stream)이라 한다. 프로그래머는 디폴트 스트림을 사용하지 않고 새로운 스트림을 생성하여 사용할 수 있으며 이를 넌디폴트스트림(non-default stream) 여러개의 스트림을 사용하므로써 병렬화를 통해 어플리케이션의 속도성능을 향상시킬 수 있다.
Rules Governing the Behavior of CUDA Streams
CUDA 스트림을 위해선 아래와 같은 몇가지 규칙이 있으며 이를 통해 효율적인 파이프라인을 구성할 수 있도록 한다.
•
주어진 스트림 내부에서의 작업은 정해진 순서에 따라 동작한다.
•
서로 다른 넌-디폴트스트림(non-default stream)은 특정한 순서로 실행되지 않는다.
•
디폴트스트림은 다른 모든 스트림의 작업이 완료될 때 까지 대기하고 또한 역으로 디폴트스트림의 작업이 완료될 때 까지 다른 모든 스트림의 작업은 중지된다.
Creating, Utilizing, and Destroying Non-Default CUDA Streams
cudaStream_t stream;
// 포인터를 통해 스트림 생성
cudaStreamCreate(&stream);
// 스트림포인터는 4번째 인자로 설정된다.
// 3번째 인자는 프로그래머가 공유메모리(shared memory)에서 커널이 실행될 때
// 블록당 바이트(bytes)의 개수를 동적으로 할당할 수 있도록 한다.
// 공유메모리당 블록에 할당되는 바이트 개수의 기본값은 0으로 해당값을 넘겨주면 된다.
someKernel<<<number_of_blocks, threads_per_block, 0, stream>>>();
// 포인터가 아닌 값(value)를 인자로 넘겨 스트림을 삭제한다.
cudaStreamDestroy(stream);
C++
복사
아래 코드는 스트림을 활용하지 않는 코드와 사용한 코드의 차이를 보여준다.
__global__ void printNumber(int number)
{
printf("%d\n", number);
}
int main()
{
for (int i = 0; i < 5; ++i)
{
printNumber<<<1, 1>>>(i);
}
cudaDeviceSynchronize();
}
C++
복사
스트림을 사용하지 않은 코드
__global__ void printNumber(int number)
{
printf("%d\n", number);
}
int main()
{
for (int i = 0; i < 5; ++i)
{
cudaStream_t stream;
cudaStreamCreate(&stream);
printNumber<<<1, 1, 0, stream>>>(i);
cudaStreamDestroy(stream);
}
cudaDeviceSynchronize();
}
C++
복사
스트림을 지정하여 연산한 코드