
Abstract
Introduction
Related Work
Conformer
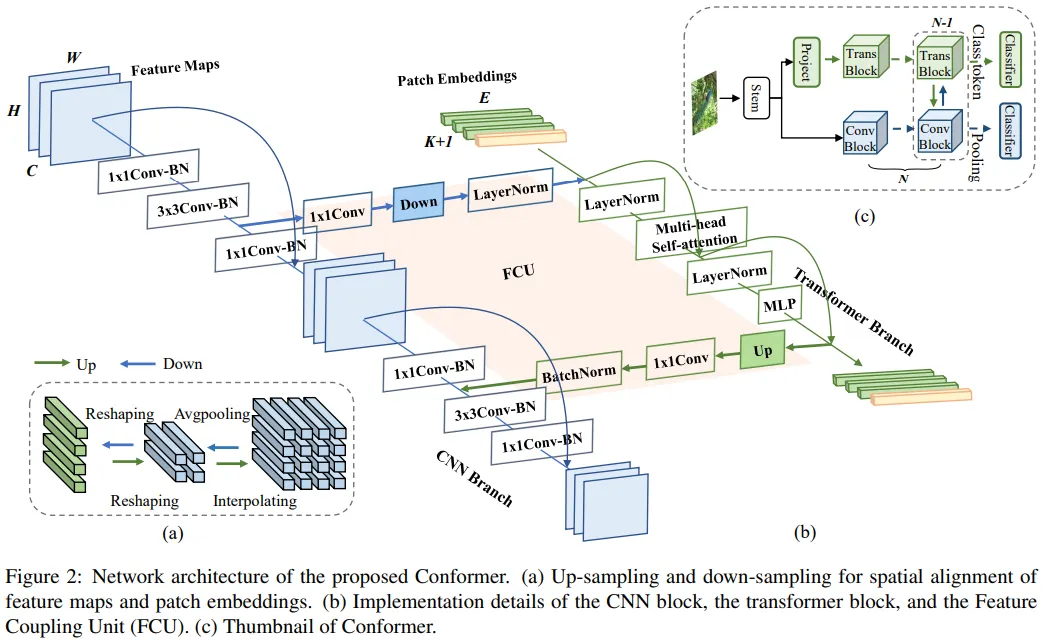
Overview
Network Structure
Analysis and Discussion
Experiments
Model Variants
CNN 브랜치와 transformer 브랜치의 파라미터 튜닝을 위해 Conformer-Ti, -S, -B 로 모델을 다양화 하였다.
Image Classification
Experimental Setting
Conformer는 1.3M개의 이미지로 구성된 ImageNet-1k를 훈련데이터로 활용하고 validation set을 테스트 데이터로 활용하였다. transformer가 유의미한 성능을 내도록 하기 위해 DeiT에 data augmentation과 정규화 기법을 적용하였다. 이 기법들은 Mixup, CutMix, Erasing, Rand Augment, Stochastic Depth 등을 포함한다. 모델은 에포크로 AdamW 옵티마이져를 통해 학습했으며 배치사이즈는 , weight decay는 로 설정하였다. 초기 학습률은 이고 decay는 코사인 스케줄(cosine schedule)를 적용하였다.
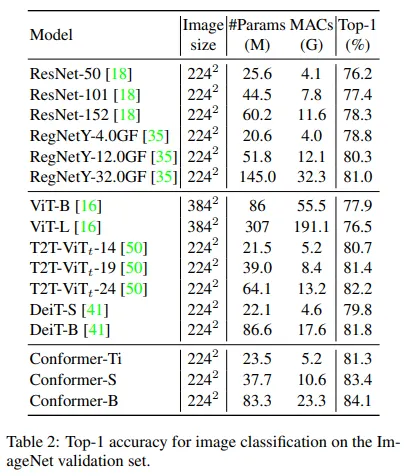
Performance
유사한 파라미터 수와 컴퓨터 자원 하에 Conformer는 CNN과 ViT보다 좋은 성능을 보였다. 단순히 성능을 넘어 Conformer는 ViT보다 빠르다.
Object Detection and Instance Segmentation
Ablation Studies
Generalization Capability
Conclusion
본 연구에선 CNN와 ViT를 합치는 새로운 이중 네트워크 구조인 Conformer를 제안하였다. Conformer를 통해 컨볼루션 연산이 local feature를 추출하고 self-attention 매커니즘이 global representation을 추출 할 수 있도록 하였다. 실험을 통해 Conformer가 유사한 컴퓨팅 연산과 파라미터에서도 CNN과 ViT의 성능을 모두 능가함을 보였다. downstream 태스크에서 본 구조가 간단하고 효율적이면서도 가장 좋은 백본 네트워크임을 확인하였다.