요약
현재 SOTA 논문들도 부분적으로 가려진 영상에 대해 민감한(sensitive)한 문제가 있다. 본 연구에서는 이를 해결하기 위해 soft attention 방식을 적용하였다. Attention mask는 body-part-guide를 위해 설계되었다. 본 연구에서는 현재 SOTA 모델들이 global featrue를 표현하기 때문에 작은 occlusion에도 민감하게 반응한다고 주장한다. 이에 대한 해결법으로 part-guided attention 방식을 통해 각 바디파츠에 보이느냐 안보이느냐의 정보를 활용하여 가려진 부분들을 추론하기 위해 주변 정보를 활용할 수 있게 하였다.

[요약정리]
문제 상황: 기존 모델들은 전체가 아닌 한개 조인트만 가려지는 등의 작은 occlusion에 대해서도 전체 성능이 떨어지는 문제가 생긴다.
이를 해결하기 위해 본 연구는 두가지 태스크로 진행한다.
1. end-to-end 방식으로 3D body parameter를 regression 한다.
2. body part에 대한 attention weight를 학습한다.
평가 데이터셋: 3DPW, 3DOH, 3DPW-OCC
Occlusion sensitivity Analysis
Error heatmap을 이용하여 시각화 진행. gt값과 추정한 joint 사이의 유클리디언 거리를 계산함. 각 pixel에 대해 occluder가 해당픽셀에 있을 때 error를 계산. occluder(occlusion을 만들어줌)는 회색 마스크로 이미지 사이즈: 224x224에 패치를 40x40으로 설정함
[SPIN의 결과 해석]

1.
error heatmap의 값이 배경부분은 작음 ⇒ SPIN이 실제로 의미있는 부분(배경이 아닌부분)을 잘 학습했음
2.
가려진 조인트의 경우 error heatmap의 값이 작음 ⇒ 기존 가설대로 가려진 영역에 민감함
3.
자연스럽게 가려진 경우 다른 조인트의 영역에 의존한다(⇒신체에 의해 가려짐을 뜻하는것 같음)
4.
한개 조인트만 잘못되도 전체 조인트가 틀어짐
Method
SOTA 네트워크들은 global average pooling 후에 제한된 공간정보가 있을지라도 의미있는 구역을 학습하려고 한다.
각 바디파트가 보이느냐 보이지 않느냐(가려져 있느냐 아니냐)를 더 잘 이해하기 위해서 PARE는 pixel-aligned 구조를 활용하였다. 각 픽셀은 이미지의 영역에 해당하고 feature volume이라 불리는 픽셀 레벨의 형태로 저장한다.
또한 어텐션 weight를 추정하는 것과 3D 포즈를 end-to-end로 학습시키는것은 서로 다른 태스크기 때문에 PARE는 두 개의 feature volume을 가진다. 따라서 attention weight를 추정하기 위한 2D part branch와 SMPL 파라미터를 추정하기 위한 3D body pose branch로 구성하였다. 마지막으로 바디파트의 종속성을 모델링 하기 위해 soft 어텐션 마스크로 파트 세그멘테이션을 사용하여 3D body branch에서 각 조인트에 대해 각 특징값의 영향도를 조정하였다.
모델 아키텍쳐와 손실함수
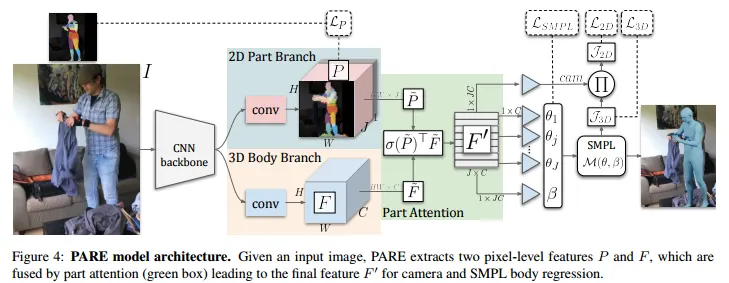
먼저 이미지 는 CNN기반의 backbone으로 들어가 volumetric feature를 추출한 후 두 개의 volumetric image feature를 추출하기 위한 두 개의 branch로 나눠진다.
2D Part Branch는 로 는 part attention과 1개의 백그라운드 마스크로 이다.
나머지 브랜치인 3D Body Branch는 이며 3D Body Parameter를 추정한다. 두 브랜치는 같은 크기의 를 가지고 다른 를 가진다.
번째 를 , 번째 를 라고 마지막 feature tensor를 라 하면 아래 식으로 표현할 수 있다.
은 아다마르 곱(Hadamard product) 이며 크기가 같은 두 행렬의 각 성분을 곱한것을 의미한다. 즉, 를 soft attention mask로 사용하였다. 이 과정은 dot product로써 효율적이며 기존 attention 방식과 동일하게 동작한다. 결국 attention을 통해 특정 픽셀이 높은 attention weight를 가진다면 해당 픽셀이 에 좀 더 영향을 많이 주도록 한다.
본 연구에서 attention map 학습을 위해 바디파트의 GT segmentation label를 지도학습하였다. 가려진 영역은 GT가 존재하지 않기 때문에 0으로 두었다. 훈련 과정 중에 바디파트에 대한 attention map의 값이 모두 0으로 나오면 의미도 없을 뿐더러 softmax 함수는 모든 원소의 합이 1이어야 하므로 사실상 연산이 불가능하다. 때문에 초기 stage에서만 지도학습을 하고 이후는 정답값없이 훈련을 진행하였다. 이 과정을 통해 네트워크가 가려진 관절의 pose를 추정하기 위해 다른 영역을 활용하도록 하였다.
는 을 이용하여 구하고 는 를 projection하여 구한다(). 는 part segmentation loss로 를 softmax 함수를 지난후의 값과 와의 cross-entropy loss로 구한다. 는 에서의 값이고 같은 위치의 GT part label는 이며 각 위치의 값은 one-hot vector로 표현하였다.
자세한 설정값들
위에서 설명한것 처럼 를 이용한 바디파츠의 라벨 지도학습은 훈련과정중 초기 stage에만 적용된다. 이 과정은 후에 를 0으로 세팅하고 이후 attention 방식을 soft-attention을 활용한 비지도 학습을 이용한다. occlusion으로 인한 바디파츠의 부재는 본 연구의 훈련에서 가장 주요한 부분이다. 를 0으로 만들면 attention 메카니즘이 바디바츠에 해당하는 부분 뿐 만 아니라 다른 픽셀에 관한것도 고려할 수 있도록 만들 수 있다. 때문에 마지막 attention map의 경우는 바디파츠의 세그멘테이션 맵과 비슷할 필요는 없다.

만약에 바디파츠가 보인다면 바디파츠에 직접적으로 집중하고 만약에 가려져 보이지 않으면 이미지에서 이를 위한 다른 지역 정보에 집중하게 된다.
본 연구에선 백본으로 ResNet-50과 HRNet-W32를 활용하였다. ResNet-50은 global average pooling 전에 7x7x2048 크기의 feature volume을 추출하였다. 2D와 3D 브랜치를 위해 3x3 컨볼루션과 배치정규와 ReLU를 이용한 2개의 upsampling 레이어를 적용하였다.
Part attention map을 구하기 위해 2D Part feature에 컨볼루션 커널을 적용하여 채널을 줄였다. 마지막 feature 로 부터 를 얻은 후에 각 의 관절 rotation 를 얻기위해 linear layer를 적용하였다. 입력 사이즈는 로 하였고 옵티마이저는 Adam으로 learning reate는 에 배치사이즈는 64로 적용하였다.
실험 내용
훈련
COCO, MPII, LSPET, MPI-INF-3DHP, Human3.6M 데이터셋을 활용하였다. 실외데이터의 경우 EFT를 통해 Pseudo-GT SMPL 데이터를 추출하였다. SMPL의 관절 24개에 대한 part segmentation을 라벨링 하여 활용하였다.
ablation 실험을 위해 COCO 데이터셋에 175K 번 학습시켰고 3DPW와 3DPW-OOC 데이터셋을 활용하였다. 그 후에 SOTA 메소드와 PARE의 성능 비교를 위해 나머지 데이터셋을 학습시켰다. 이 방법을 통해 전체 훈련시간을 줄였고 최종적으로 RTX2080ti GPU에서 72시간의 학습시간이 걸렸다.
occlusion 에 강건한 모델을 위해 일반적은 occlusion augmentation 테크닉을 활용하였다 → synthetic occlusion(SynthOcc), random crop (RandCrop).
평가
3DPW의 테스트 데이터와 3DPW-OCC와 3DOH 데이터셋이 평가용으로 쓰였다. 평가 지표로 PA-MPJPE와 MPJPE를 mm 단위로 활용하였다. 3DPW에 대해선 PVE도 mm 단위로 평가하였다.
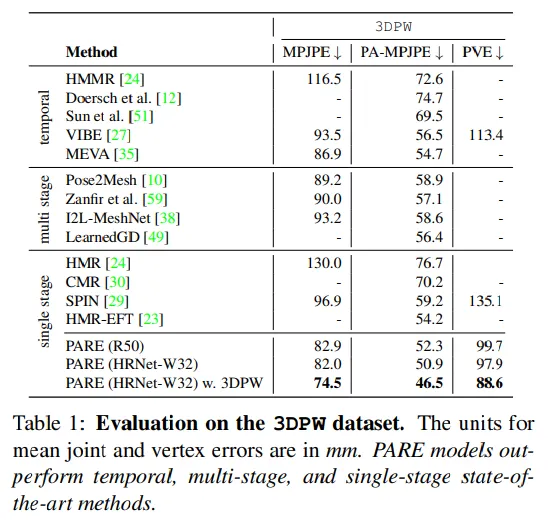
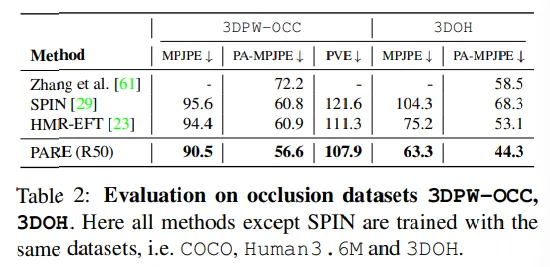
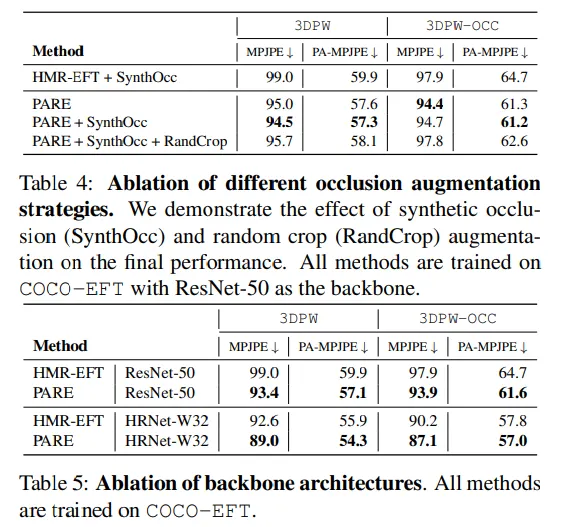

결론

PARE에서 실패한 이미지들
본 연구에서는 새로운 Part Attention Regressor인 PARE를 제안하여 각 독립적인 바디파츠의 가시성에 대한 정보를 표현하므로써 occlusion에 강건함을 얻었다. 특히 바디파츠가 보이지 않았을 때 보이는 부분에 의존하므로써 이러한 부분을 커버하였다.
위 사진은 잘 안된 케이스들이며
(a-b)은 crop된 영역에 너무 많은 사람이 있는경우,
(b-d)는 어려운 자세 또는 모호한 자세일 때,
(e-f)는 어린이 일 때,
(g-h)는 occlusion이 너무 심할 때다.