•
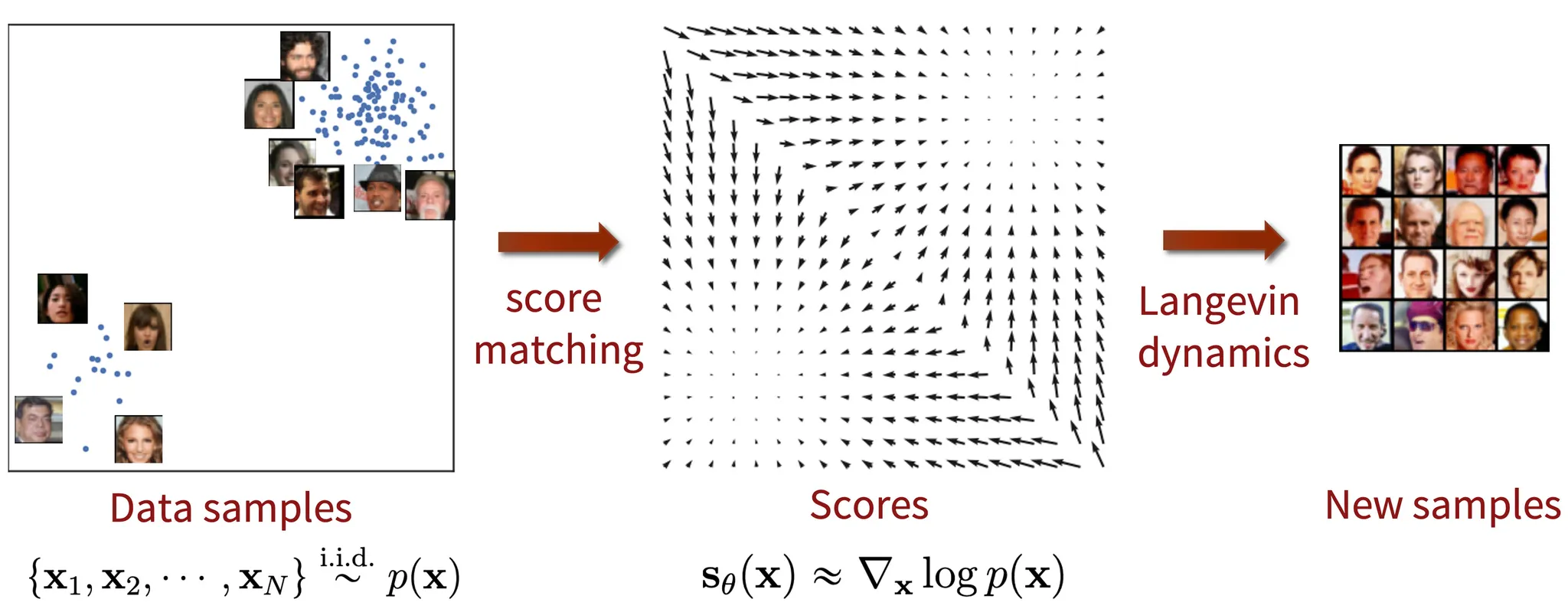
score-based generative model는 원본데이터 분포로 부터 샘플링하는 방식을 통해 이미지를 생성하는 모델이며 이를 위해 주어진 데이터 분포로 부터 새로운 샘플을 생성하는 모델을 학습시킴
•
GAN과 VAE 두 방식 모두 추가적인 분포인 를 포함해야 함(GAN에서는 노이즈 분포, VAE에선 잠재변수에 대한 사전확률분포)
•
score-based generative model을 사용하면 기존 likelihood 기반의 모델처럼 추가적인 분포를 활용할 필요가 없음
•
확률분포를 샘플링 하기위한 방법중 하나는 Langevin dynamics라 불리는 반복프로세스며 MCMC 알고리즘과 같이 다음샘플을 뽑을때 이전샘플을 참고. 수식으로 표현하면 아래와 같음
•
은 로 부터 얻은 샘플, 은 score function, 은 노이즈를 추가하기 위한 항이며 로 부터 다음 샘플인 을 구하도록 구성
•
score function은 기울기를 의미하며 score matching은 실제 확률밀도함수를 구하는게 아닌 score function을 이용한 score값을 이용하여 확률밀도함수를 추정하는것을 의미
•
즉, GAN이나 VAE처럼 바로 분포의 차이를 구하는게 아니라 score function을 사용해서 각 분포의 score를 구한 후 두 score의 차이를 구함
•
그러나 score function을 계산하기 위해 실제 데이터의 분포인 를 아는것은 불가능하기 때문에 를 로 근사하며 이는 로 학습된 모델의 출력이 됨
•
때문에 학습할 모델은 입력값 를 받아 확률분포 를 출력하지만 모델의 출력값이 확률분포의 가장 기본적인 특징이 되는 라는 성질을 만족하는 지 확신할 수 없음
•
때문에 적분값이 1이 아닌 확률분포인 을 출력하게 하고 를 통해 정규화된 분포를 구함
•
아래 수식을 통해 확인할 수 있듯이 score function을 이용하여 를 구하는것과 를 구하는것이 동일한 결과를 가지므로 를 구하는것 만으로도 충분함
•
정리하면 아래와 같은 최적화함수를 설계할 수 있으며 이를 explicit score matching이라고 함
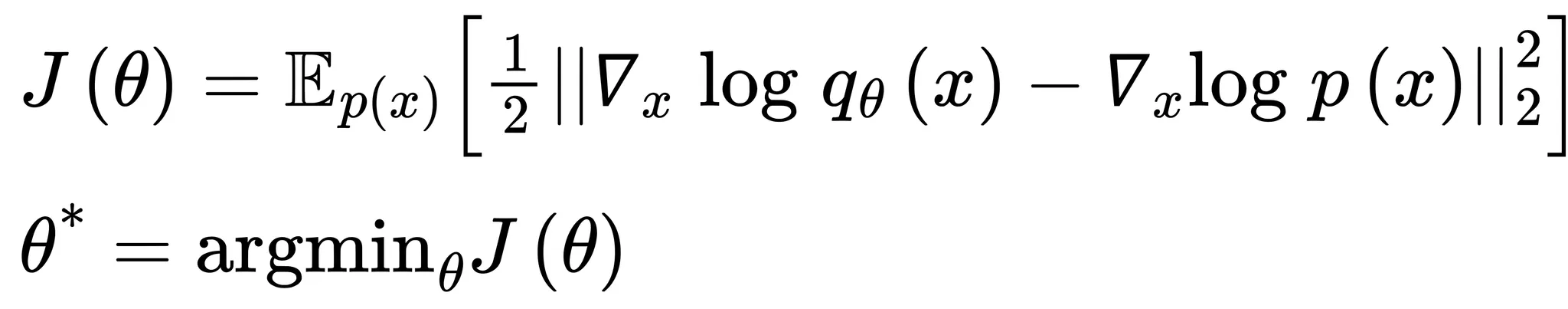
•
explicit score matching 식에 대해 라 하면 아래 좌항과 같이 표현할 수 있으며 우항처럼 연산하는 방식을 implicit score matching라 함
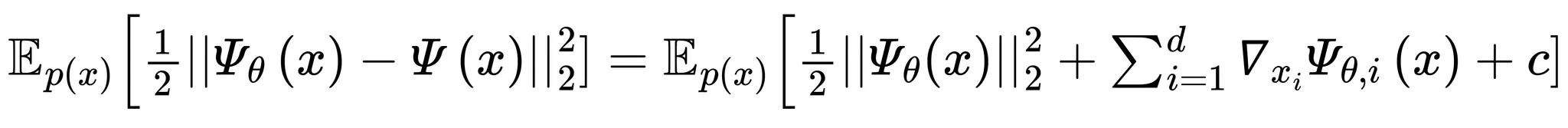

총 과정 정리
1.
학습된 네트워크를 통해 샘플을 생성하고 결과의 로그값을 가져와 역전파(backpropagation)과정 진행
2.
로 부터 을 샘플링
3.
1번과 2번 결과를 Langevin dynamics 방정식에 넣어 다음 샘플 을 구함
4.
을 이용하여 1번부터 3번까지 과정을 반복
예시 코드
# this code is made by chatgpt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# 하이퍼파라미터 설정
batch_size = 64
learning_rate = 2e-4
num_epochs = 50
num_steps = 500
sigma_min = 0.01
sigma_max = 1.0
# 데이터 전처리 및 로드
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Score-based Generative Model 정의
class ScoreNet(nn.Module):
def __init__(self):
super(ScoreNet, self).__init__()
self.net = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 28*28)
)
def forward(self, x, sigma):
x = x.view(-1, 28*28)
score = self.net(x)
return score / sigma.view(-1, 1)
# 모델 초기화
score_model = ScoreNet().cuda()
optimizer = optim.Adam(score_model.parameters(), lr=learning_rate)
# 노이즈 스케줄 함수 정의
def noise_schedule(t, sigma_min=sigma_min, sigma_max=sigma_max):
return sigma_min * (sigma_max / sigma_min) ** t
# Score Matching 손실 함수 정의
def score_matching_loss(model, x):
batch_size = x.size(0)
t = torch.rand(batch_size, device=x.device)
sigma = noise_schedule(t).view(-1, 1, 1, 1)
noise = torch.randn_like(x) * sigma
perturbed_x = x + noise
score = model(perturbed_x, sigma)
target = -noise / sigma
loss = (score - target).pow(2).mean()
return loss
# 학습 루프
for epoch in range(num_epochs):
total_loss = 0
for x, _ in train_loader:
x = x.cuda()
optimizer.zero_grad()
loss = score_matching_loss(score_model, x)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss/len(train_loader):.4f}')
# 샘플링 함수 정의
def sample(score_model, num_samples=64, num_steps=num_steps, device='cuda'):
score_model.eval()
samples = torch.randn(num_samples, 1, 28, 28, device=device)
step_size = 1 / num_steps
for t in reversed(range(num_steps)):
t = torch.tensor([t / num_steps], device=device)
sigma = noise_schedule(t).view(-1, 1, 1, 1)
noise = torch.randn_like(samples) * np.sqrt(step_size)
with torch.no_grad():
score = score_model(samples, sigma)
samples = samples + step_size * score + noise
return samples.cpu()
# 샘플링
samples = sample(score_model, num_samples=16)
samples = samples.view(-1, 1, 28, 28)
Python
복사
출처
•
Fundamentals of Deep Learning, 2nd Edition by Nithin Buduma, Nikhil Buduma, Joe Papa