
GAN 모델이란?
•
GAN은 노이즈로 부터 이미지와 같은 실제같은 샘들을 생성하기 위해 디자인된 생성모델
•
GAN모델은 discriminator와 generator로 나뉘어있음
•
generator는 어떤 노이즈 분포(다중 가우시안 분포 등)로부터 샘플을 받아 이미지를 생성
•
discriminator는 generator로 부터 만들어진 이미지인지 원본데이터 이미지인지 예측
•
generator는 discriminator가 원본과 생성된 이미지를 구분할 수 없을 때 까지 학습
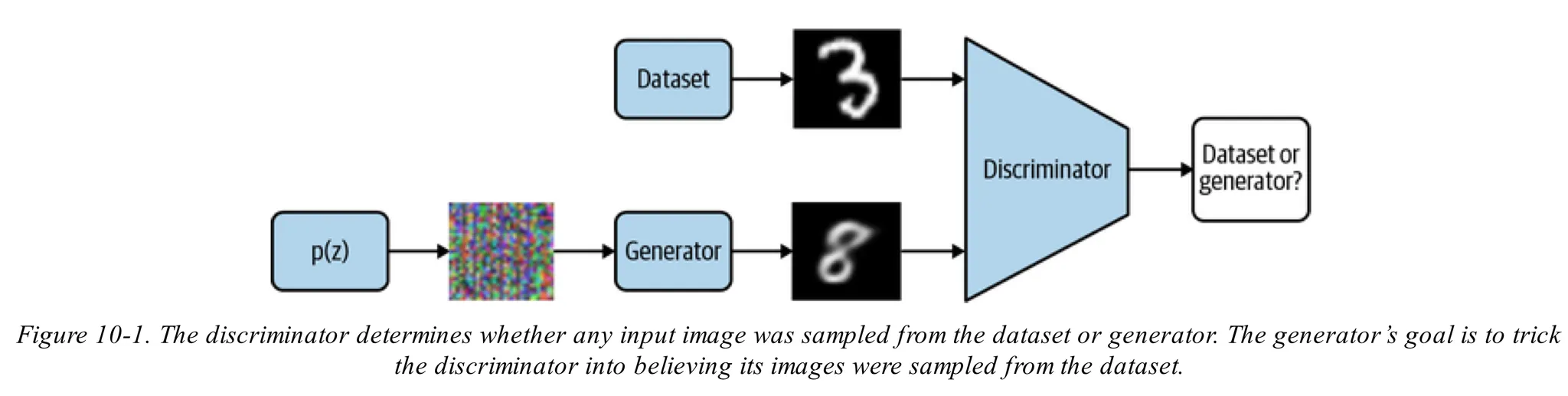
GAN 모델 전체 파이프라인
•
학습이 잘 이뤄진다면 원본데이터 분포와 생성한 이미지의 분포가 같아야 하므로 모든 에 대해서 이 성립해야함
•
는 생성한 이미지이냐 원본이미지이냐이므로 이진분류이며 이에 따라 베르누이 분포를 따름
•
는 노이즈분포를 데이터 공간으로 매핑시키며 는 입력이미지가 원본일 확률을 구하며 는 위 손실함수를 최소화하도록, 는 최대화 하도록 하는 파라미터를 학습시키며 이에 따라 최적화 함수는 아래와 같이 정리됨
Discriminator 학습시키기
•
discriminator를 학습시키 위해 generator는 고정하며 아래 식을 통해 구함
•
위 식을 간소화 하여 는 아래와 같은 점수함수를 최대화하도록 학습함
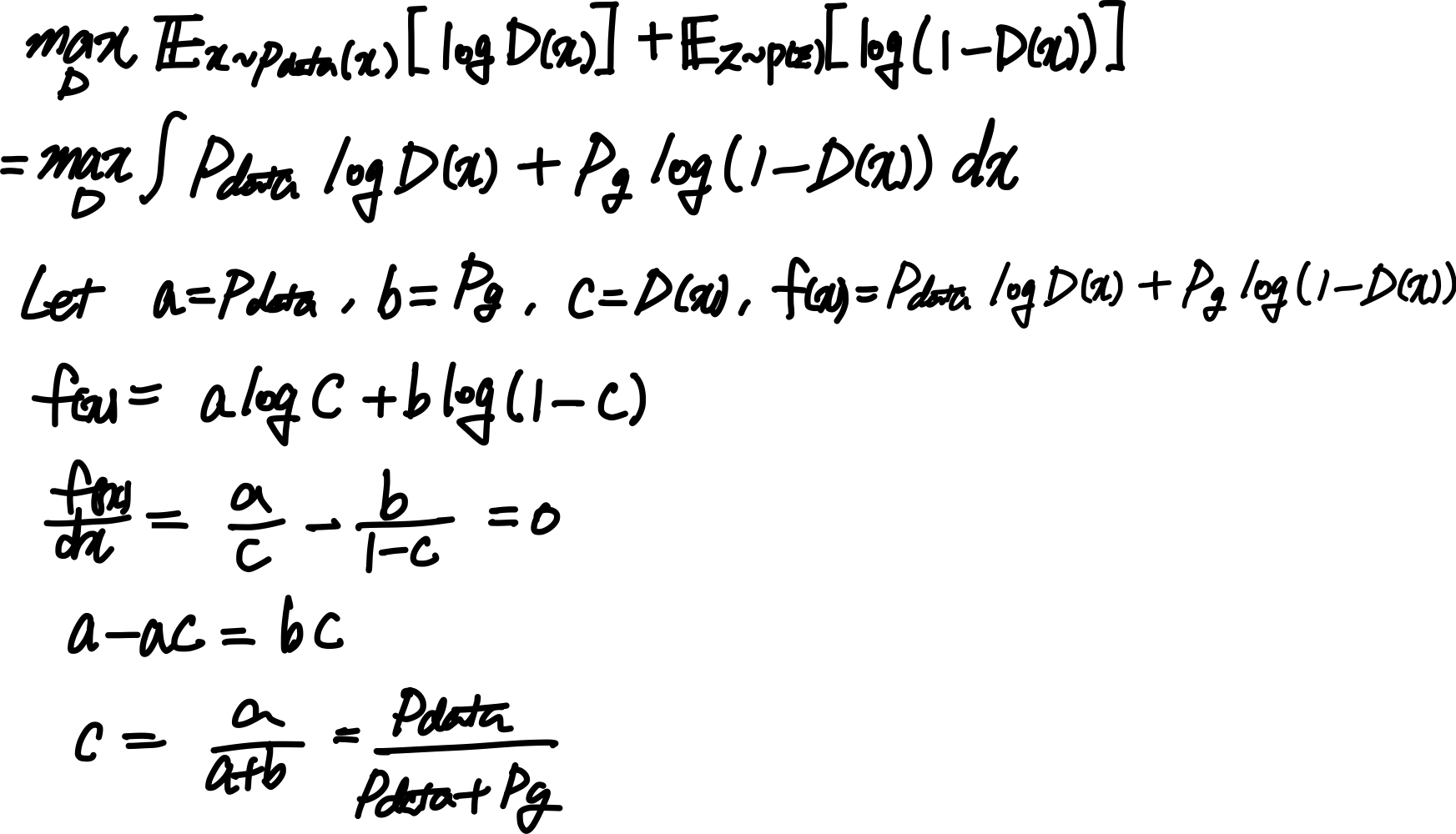
식 유도 과정
•
또한 데이터셋으로 부터 가져온 샘플의 우도와 generator로부터 가져온 샘플의 우도가 같은것을 이용하면 이므로 아래와 같이 더 간소화 시킬 수 있음

•
위 식을 손실함수 에 대입하면 아래와 같이 정리되며 는 파라미터이고 는 의 파라미터임
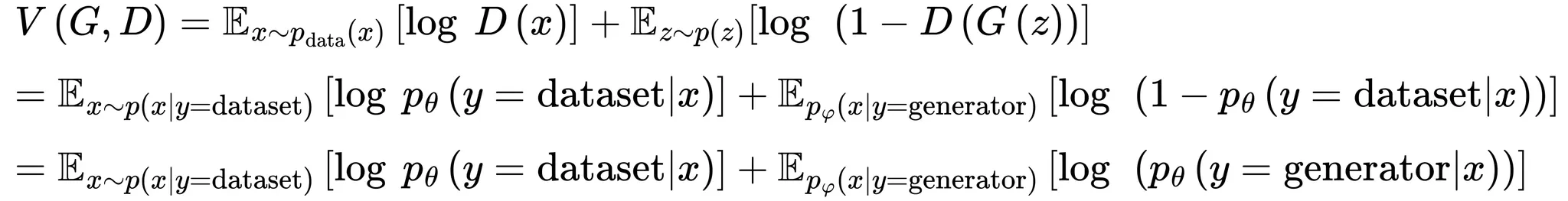
•
식을 좀 더 자세히 보면 두 크로스엔트로피 항의 합으로 표현이 가능함
•
위 크로스엔트로피 식을 적용하면 의 최적파라미터 는 아래과 같이 적용할 수 있음
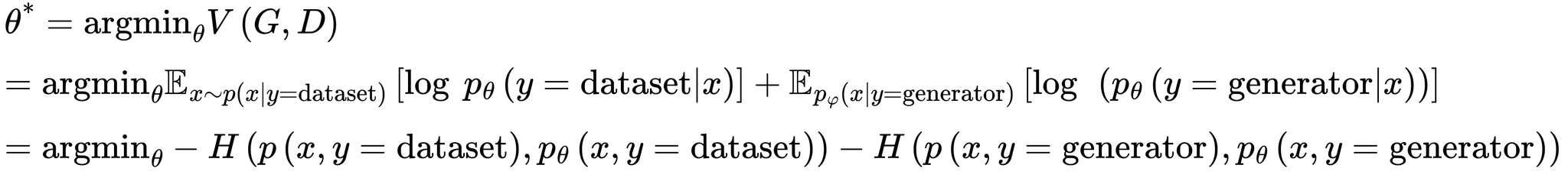
Generator 학습시키기
•
위 최적화 과정을 진행할땐 discriminator를 학습시킬때와는 반대로 를 고정()하며 이에 따라 최적화 된 를 손실함수에 대입하면 아래와 같이 정리할 수 있음
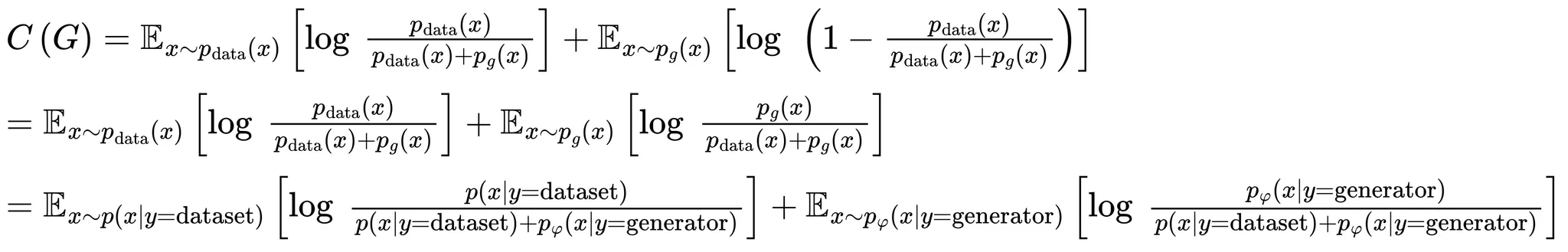
예시코드
# this source code is made by chatgpt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torchvision import datasets, transforms
from torchvision.utils import save_image
import os
# 결과 이미지를 저장할 디렉토리 생성
if not os.path.exists('gan_images'):
os.makedirs('gan_images')
# 하이퍼파라미터 설정
batch_size = 64
lr = 0.0002
latent_dim = 100
image_size = 784 # 28*28
n_epochs = 50
sample_interval = 400
# 데이터셋 로드 및 전처리
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True, transform=transform),
batch_size=batch_size, shuffle=True
)
# 생성자(Generator) 정의
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, image_size),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), 1, 28, 28)
return img
# 판별자(Discriminator) 정의
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(image_size, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# 모델 초기화
generator = Generator()
discriminator = Discriminator()
# 손실 함수
adversarial_loss = nn.BCELoss()
# GPU 사용 가능 시 GPU로 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
generator.to(device)
discriminator.to(device)
adversarial_loss.to(device)
# 최적화 설정
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
# 학습 시작
for epoch in range(n_epochs):
for i, (imgs, _) in enumerate(train_loader):
# 진짜 및 가짜 레이블 생성
real = Variable(torch.ones(imgs.size(0), 1)).to(device)
fake = Variable(torch.zeros(imgs.size(0), 1)).to(device)
# 입력 이미지 설정
real_imgs = Variable(imgs).to(device)
# ---------------------
# 판별자 학습
# ---------------------
optimizer_D.zero_grad()
# 진짜 이미지에 대한 판별자 손실 계산
real_loss = adversarial_loss(discriminator(real_imgs), real)
# 가짜 이미지 생성
z = Variable(torch.randn(imgs.size(0), latent_dim)).to(device)
gen_imgs = generator(z)
# 가짜 이미지에 대한 판별자 손실 계산
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
# 총 판별자 손실 계산 및 역전파
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# -----------------
# 생성자 학습
# -----------------
optimizer_G.zero_grad()
# 생성된 이미지의 생성자 손실 계산
g_loss = adversarial_loss(discriminator(gen_imgs), real)
# 생성자 손실 역전파 및 최적화
g_loss.backward()
optimizer_G.step()
# 학습 과정 출력
if i % sample_interval == 0:
print(f"Epoch [{epoch}/{n_epochs}] Batch [{i}/{len(train_loader)}] \
Loss D: {d_loss.item():.4f}, Loss G: {g_loss.item():.4f}")
# 에포크가 끝날 때마다 이미지 샘플 저장
save_image(gen_imgs.data[:25], f"gan_images/{epoch}.png", nrow=5, normalize=True)
Python
복사
출처
•
Fundamentals of Deep Learning, 2nd Edition by Nithin Buduma, Nikhil Buduma, Joe Papa