
본 연구노트에서는 3D Pose and Shape estimation 분야의 데이터 AGORA에 대한 논문을 리뷰합니다. 본 연구에선 데이터의 생성과 수량, 평가방법등을 소개하고 있지만 본 연구노트는 이 데이터의 생성방법에 대한 부분만 기술하였습니다.
자세한 내용은 논문을 통해 확인 바랍니다.
요약
3D Human pose estimation 분야에 여러 데이터셋이 있다. 그러나 다양한 옷이나 가려진 상황, 다양한 환경이 포함된 데이터는 구축하기가 힘들다. 게다가 현재 데이터셋은 몸의 주 관절에 관한 부분만 평가에 포함하여 손(hand)나 얼굴(face)에 대한 부분은 제외되어 있다. 본 연구는 이러한 기존 데이터셋의 한계를 해결하기 위한 가상 데이터셋(synthetic dataset)을 구축한 논문이며 특히 4240개의 상업 이용이 가능한 다양한 포즈와 여러 옷을 포함한 스캔 데이터 또한 제공한다. 여기엔 257개의 아이들 데이터 또한 포함되어 있다. 본 연구에서는 이 스캔데이터와 SMPL-X를 이용한 3D pose와 shape이 fitting된 SMPL-X 데이터셋을 제공한다. 14K의 훈련데이터와 3K의 테스트데이터로 구성되며 이미지당 5명에서 15명의 사람이 포함되어 있다. 본 연구는 특히 아이들에 대한 SMPL 데이터셋을 구축하는데 해결책을 제시했다는 것에도 의의가 있다.
Method: Obtaining reference data
AGORA 데이터셋을 구축하기 위해 본 연구에서는 고품질의 스캔데이터를 구매하여 활용하였다. 스캔데이터는 3DPeople, AXYZ, Human Alloy, Renderpeople로 텍스쳐를 포함하고 있으며 여기서 350개의 subject를 구성하기 위해 4240개의 스캔데이터를 선정하였다. 스캔데이터는 로 표현되며 3차원 좌표는 과 그 연결(face) 로 구성되어 로 표현된다. 본 연구에선 스캔데이터 에 SMPL-X 모델 를 피팅시켰으며 모델 파라미터는 로 구성된다.
먼저 랜드마크가 되는 2D Keypoint를 이용하는 기존의 single-view 기반의 SMPLify-X를 확장하여 multi-view기반으로 피팅을 진행했다. 그러나 2D Keypoint는 body shape을 추정하기엔 너무 적은 정보를 가지고 있다. 때문에 3D scan 데이터에 피팅하는 과정을 진행하려 했으나 스캔데이터의 경우 옷이나 머리가 피팅에 방해가 된다. 이를 개선하기 위해 본 연구에서는 아래와 같이 옷 안의 body shape을 피팅하기 위한 방식을 제안하였다.
먼저 피부와 옷에 관련한 손실값 과 를 정의하였다. 두 손실값 다 모델의 표면이 스캔데이터와 가까워지도록 설계되며 추가로 는 몸의 vertices가 옷의 바깥에 나갔을때 패널티를 준다.
스캔데이터의 피부부분과 옷 부분을 구분하기 위해 본 연구에서는 Graphonomy 모델을 이용하여 스캔데이터를 피부부분과 옷 부분을 라벨링하였다. 본 연구에선 과 뿐 만 아니라 2D landmark에 대한 손실값 를 통해 projection된 키포인트와 정답 키포인트 사이의 차이를 반영하여 다중카메라에 대해 SMPL-X 파라미터를 피팅하였다. 이 과정의 전체 파이프라인은 아래 그림과 같다.
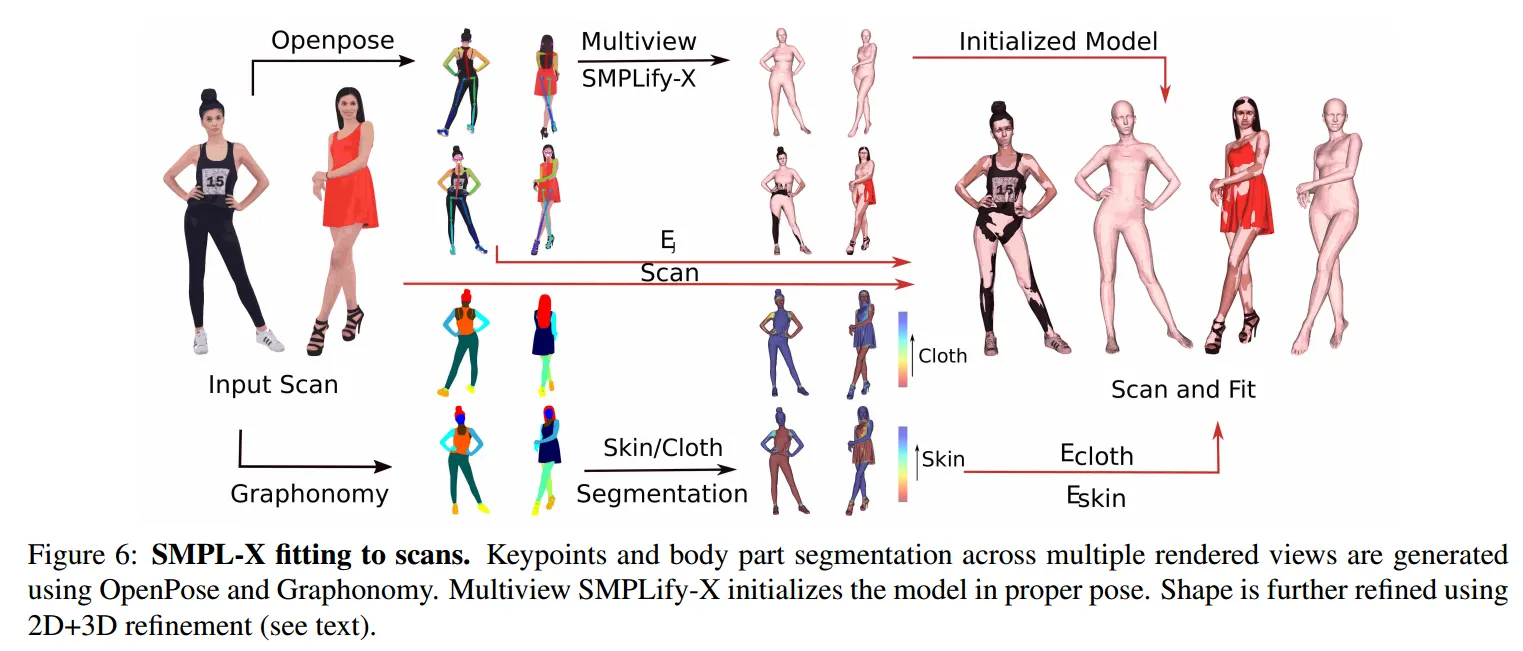
Multi-view Initialization
스캔데이터는 다양한 포즈와, 옷, 그리고 물체를 잡은 사람들을 포함한다. 때문에 좋은 초기화 과정 없이 피팅을 하면 정확도가 떨어지게 된다. 먼저 스캔데이터를 각 카메라 에 렌더링하여 이미지를 만든다. 이 이미지를 Openpose를 통해 2D 키포인트를 라벨링한다. 다음 각 카메라에 라벨링된 키포인트를 통해 멀티뷰방식의 SMPLify-X 알고리즘을 적용하여 SMPL파라미터를 초기화 한다.
SMPLify-X는 한개 이미지만을 입력으로 받아 아래와 같은 손실함수를 통해 포즈파라미터 , 형태파라미터 , 얼굴표현파라미터(facial expression) 를 추정한다.
는 추정된 3차원 키포인트를 이미지에 투영하여 얻은 2차원 관절좌표와 정답값 사이의 손실값이고 는 몇가지 정규화값을 포함한다. 는 팔꿈치와 무릎의 손실값을 좀 더 강하게 주는 역할을 하고 는 메쉬끼리의 겹치는 것을 방지하도록 한다. 는 body pose, hand pose, body shape 그리고 facial expression에 대한 prior이다. 최종적으로 멀티뷰에 대한 손실값은 가 되며 카메라 내외부 파라미터가 제공되기 때문에 카메라 translation값에 대해선 추정할 필요가 없다.
2D+3D Refinement
스캔데이터의 vertices를 피부부분과 옷 부분으로 분리하기 위해 세그멘테이션 마스크를 사용하였다. 세그멘테이션 마스크를 만들기 위해 Graphonomy 모델을 활용했으며 이 모델은 주어진 이미지에 대한 part-segmentation을 바디파츠 뿐 만 아니라 옷에 대한 부분도 추출해준다.
Skin-Cloth Segmentation
스캔데이터를 멀티뷰 카메라에 렌더링하여 얻은 이미지에 Graphonomy 모델을 통해 각 바디파츠와 옷들의 세그멘테이션 마스크를 추출한다. 본 연구에선 이를 피부, 옷, 그리고 나머지(머리카락, 객체)로 라벨링하였다. 각 vertices를 이미지에 투영하여 세그멘테이션 마스크와 비교함으로써 vertices를 라벨링한다.
Skin term
각 스캔데이터의 vertex 와 모델 출력값의 triangle 중 가장 가까운 triangle 사이의 거리를 잰다. 점과 평면사이의 거리를 최소화시키도록 손실함수를 설계했으며 의 확률값을 가중치로 둔다. 은 vertex 가 피부에 속할 확률이며 Graphonomy 모델을 통해 계산된다.
은 모델 의 표면과 scan vertex 사이의 최단거리를 구하는 함수이다. 는 Geman-McClure robust error function로 손실값의 아웃라이어를 방지한다.
Clothing term
의 목표는 모델의 출력값이 옷의 스캔값에 가장 가깝게 만들면서도 통과하지 않도록 하는것이다.
스캔데이터는 몸으로 분류되는 스캔값과 옷으로 분류되는 스캔값의 합으로 이루어져있다. 즉, 각 스캔 포인트는 바디모델에 포함될 점 와 바디모델 바깥에 있는 점 로 나뉜다. 스캔데이터값을 분류하기 위해 본 연구에서는 Graphonomy 모델을 이용하여 옷 스캔값일 확률 를 얻었다. 는 가중치 를 이용하여 거리기반의 손실함수를 주었고 는 Geman-McClure function을 이용하여 스커트나 목욕가운 등 헐렁한 옷들도 잘 반영하도록 하였다.
얼굴표현 파라미터인 는 옷과는 관련이 없기 때문에 최적화하지 않고 고정하였다.
각 점 는 모델로 부터 나온 삼각형 중 가장 가까운 삼각형 위의 점이면서 법선벡터 위의 점 을 가진다. 본 연구에서는 변위벡터 로 정의하였으며 만약에 와 의 내적값이 0보다 크면 로 분류하고 그렇지 않다면 로 분류하였다.
Fitting child scans
AGORA는 257명의 아이들 스캔데이터를 포함하고 있다. SMPL-X를 스캔데이터에 바로 피팅할때 아래 그림과 같은 왜곡이 생기게 된다.
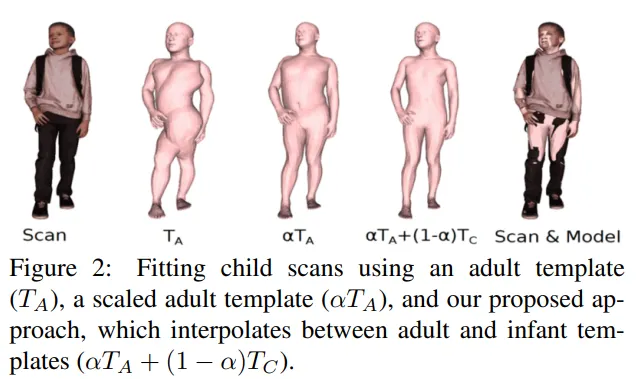
SMPL은 성인남녀를 기준으로 만들어졌기 때문에 SMPL-X 또한 아이들의 스캔값을 이용하여 피팅을 진행할 수 없기 때문에 위와 같은 왜곡이 일어나게 된다.
위의 그림에서 왼쪽에서 3번째()과 같이 스케일 파라미터 를 이용하여 해결할 수도 있지만 이는 단순히 크기를 성인에서 어린이의 크기로 줄인것이기 때문에 여전히 부자연스러운 모습을 보여준다. 이를 해결하기 위해 본 연구에선 SMPL의 유아버전인 SMIL을 SMPL-X와 같은 위상으로 변환하여 해결하고자 하였다.
해당 과정을 진행하기 위해 SMPL-X의 템플릿 와 SMIL의 템플릿 을 보간하는 과정을 통해 어린이의 모습을 표현하고자 하였다.
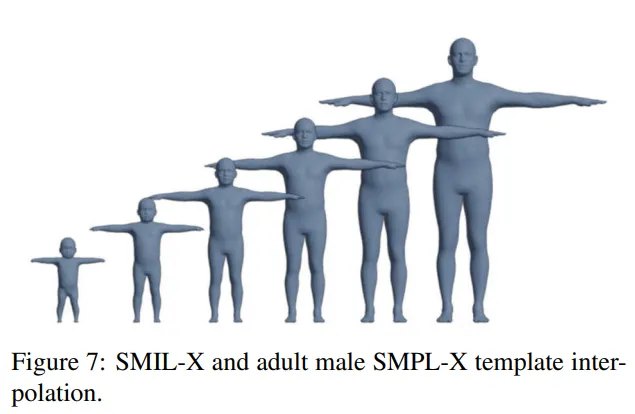
위 사진은 보간값에 따른 템플릿 변화를 보여주며 형태파라미터 를 최적화 할 때 가중치 를 같이 선형보간하였다. 이 과정을 통해 어린이의 모습을 좀 더 정확하게 표현하도록 하였다.