Abstract
현재 대부분의 연구들은 주로 모델의 구조를 만들거나 적절한 손실함수를 구성하는데 집중하고 있다. 그러나 이들은 레이어의 깊이가 깊어질수록 특징값을 추출하거나 공간적인 변형들에 있어서 정보가 손실되는 것은 신경쓰지 않고 있다. 본 연구는 깊은 네트워크를 통과할 때 발생하는 정보의 손실에 관해 다룬다. 본 연구는 PGI(programmable gradient information)이라 하는 새로운 개념을 제시하여 여러 손실함수로 부터 요구되는 다양한 변화를 다루도록 한다. PGI는 손실함수를 위한 타겟 테스크를 위한 완전한 정보를 제공할 수 있기 때문에 모델을 업데이트 할 때 더 의미있는 정보를 활용할 수 있다.
또한 새로운 경량화 모델구조로 GELAN(Generalized Efficient Layer Aggregation Network)를 제안한다. GELAN의 구조는 PGI가 경량화모델에 더 좋은 영향을 줄 수 있음을 확실하게 보여준다. GELAN과 PGI의 유효성을 검증하기 위해 MS COCO데이터셋을 이용하였다. 본 결과로 depth-wise convolution을 활용한 기존 SOTA모델 보다 conventional convolution을 활용한 GELAN이 더 좋은 결과를 보였음을 알려준다.
PGI는 가벼운 모델부터 무거운 모델까지 다양하게 활용할 수 있다. 완전한 정보를 얻기 위해 사용하므로 미리 학습된 모델 보다는 처음부터 학습된 모델이 더 좋은 결과를 가져올 수 있다.
Introduce
본 연구의 공헌내용은 아래와 같다.
1.
reversible function 관점에서 기존 모델을 이론적으로 분석하였고 이러한 과정을 통해 과거에 설명하기 어려웠던 여러 현상들을 완전히 밝혔다. 또한 이러한 분석에 기반하여 PGI와 auxiliary reversible branch를 디자인하여 좋은 결과를 얻었다.
2.
PGI는 깊은 감독학습이 극단적으로 깊은 신경망구조에서만 사용되는것을 해결하기 위한 것 이므로 새로운 경량화 구조를 만들 수 있도록 해준다.
3.
GELAN은 conventional convolution만을 활용하도록 설계되었기 때문에 depth-wise convolution에 비해 더 높은 파라미터 활용도를 가짐에도 가볍고 빠르며 정확한 장점을 가지고 있다.
4.
제안된 PGI와 GELAN을 결합하여 MSCOCO 데이터셋에서 좋은 성능을 보였다.
Related work
Reversible Architectures
reversible architecture의 단위연산은 역변환의 특징을 유지해야하므로 각 단위연산의 레이어의 특징맵의 결과가 원본 정보로 부터 완전히 복원이 가능해야한다. 본 연구에선 다양한 인공신경망 구조를 살펴본 결과 reversible properties의 다양한 자유도를 가진 많은 고성능의 구조가 있음을 확인하였다. 예를들어 Res2Net모듈은 계측정긴 방법을 통해 다음 파티션과 다른 입력 파티션을 결합하고 이들을 backward하기 전에 모든 변형된 파티션을 결합한다. CBNet은 원본정보를 얻기위해 원본 입력데이터를 반대의 백본을 통해 재생산하고 다양한 결합방법들을 통해 여러 레벨의 reversible information를 얻었다. 이러한 네트워크 구조들은 점진적으로 훌륭한 파라미터 유용성을 가지나 추론속도를 낮추는 추가적인 결합 레이어가 필요하다. DynamicDet은 CBNet과 고효율의 실시간 객체인식모듈인 YOLOv7을 결합하여 속도, 파라미터수, 정확도 모두 좋은 성능을 냈다. 본 연구는 DynamicDet구조를 reversible branch를 디자인하기 위한 기본모델로 설정하였다. 또한, 제안된 PGI엔 reversible information이 추가된다. 제안된 새로운 구조는 추론과정에서 추가적인 연결을 요구하지 않는다. 이로 인해 속도, 파라미터 수, 정확도에서 많은 장점을 가진다.
Auxiliary Supervision
Deep supervision은 가장 일반적인 Auxiliary Supervision으로 중간 레이어에 추가적인 예측 레이어를 삽입함으로써 훈련시키는 방식이다. 특히 트랜스포머 기반 방식에서 소개되는 다층 레이어 디코더(multi-layer decoders)가 가장 일반적인 방식이다. 또 다른 일반적인 Auxiliary Supervision 방식은 통합층에서 생성된 피쳐맵을 가이드하기 위해 관련있는 메타 정보를 활용하여 타겟태스크에 의해 요구되는 특징들을 만들어 내도록 하는것이다. 이러한 타입의 예시로 segmentation loss나 depth loss를 활용하여 객체인식 모델의 성능을 높이는 것 등을 들 수 있다. 그러나, Auxiliary Supervision 매커니즘은 큰 모델에만 적용이 가능하기 때문에 가벼운 모델에 적용하게 되면 성능이 오히려 떨어지게 된다. 본 연구에서 제안하는 PGI는 여러레벨의 시멘틱 정보를 재구성하는 방식으로 설계되었고 이러한 설계를 통해 경량모델 또한 Auxiliary Supervision 매커니즘의 이점을 활용할 수 있다.
Problem Statement
전통적인 인공신경망에서 그래디언트 소실이나 업데이트 크기가 0이 되는 등의 수렴 문제가 생긴다. 그러나 현대의 깊은 인공신경망들은 이미 근본적으로 위의 문제를 다양한 정규화와 활성화함수를 통해 해결했다. 그럼에도 불구하고 깊은 인공신경망은 여전히 느리거나 작은 수렴결과의 문제를 가지고 있다.
본 연구에선 위 이유에 대해 좀 더 심층적으로 탐구했다. 정보명목에 관해 좀 더 디테일하게 고민해본 결과 아주 깊은망의 경우 근본적으로 초기 미분값이 사라지는 문제가 있었다. 이를 확인하기 위해 초기 가중치와 함께 서로 다른 여러 네트워크를 동작시켰고 이를 아래 그림 2와 같이 시각화 시켰다. 명백하게 깊은망에서 PlainNet은 객체인식에 필요한 중요한 정보를 잃었다.

Information Bottleneck Principle
정보병목에 관한 부분에 있어서 데이터 에 대해 변환이 진행될 때 정보가 손실되는것을 아래 방정식과 같이 확인할 수 있다.
여기서 는 상호정보(mutual information)를 의미하고, 와 는 변형함수(transformation function), 그리고 와 는 각각 와 의 파라미터를 의미한다.
심층신경망에서 과 은 딥러닝에서 두개 연속층의 연산을 의미한다. 위 방정식에서 네트워크의 레이어의 크기가 커질수록 원본 데이터는 더 많이 손실됨을 확인할 수 있다. 그러나, 깊은 인공신경망의 파라미터는 네트워크의 출력 뿐 만 아니라 주어진 타겟에도 영향을 받고 손실함수를 계산 후에 새로운 기울기를 생성하여 네트워크를 업데이트 하게 된다. 이를 통해 네트워크의 깊이가 깊어질수록 예측된 타겟에 관한 완전한 정보를 남기기 어렵다는걸 알 수 있다. 이로인해 네트워크 훈련중에 완전하지 못한 정보를 활용하게 되어 신뢰할 수 없는 기울기를 갖고 수렴이 잘 안되게 된다.
모델의 크기를 키우는건 위 문제를 해결하는 방식 중 하나가 된다. 모델을 구성하기 위해 많은 수의 파라미터를 사용하면 데이터를 더 완벽하게 변환할 수 있다. 위 방식은 데이터가 추론되는 과정에서 정보가 손실되더라도 타겟에 매핑하기 위한 충분한 정보를 갖게 된다. 이러한 현상은 왜 현대 모델에서 깊이보다 너비가 중요한지를 보여준다. 그러나 위 결론은 근본적으로 아주 깊은 신경망에서 신뢰할수 없는 미분값 문제를 해결할 순 없다. 다음장에서 어떻게 Reversible Function를 사용하여 문제를 해결하는 방식을 소개하고 분석한다.
Reversible Function
함수 이 반전변환 를 가질 때, 이를 reversible function이라 하며 식은 아래와 같다.
여기서 와 는 와 의 파라미터이다. 데이터 는 아래 방정식과 같이 정보손실없이 reversible function에 의해 변환된다.
네트워크의 변환함수가 reversible function으로 구성되었을 때 모델 업데이트 과정에서 얻어진 미분값이 더 신뢰가능하다. 거의 모든 딥러닝 모델의 구조가 아래 방정식과 같은 reversible한 특징을 가진다.
여기서 은 PreAct ResNet의 번째 레이어를 의미하고 는 번째 레이어의 변환함수다. PreAct ResNet은 반복적으로 원본 데이터 를 뒤쪽 레이어에 명시적인 방식으로 보내게 된다. 이러한 구조가 1000개 이상의 층을 갖는 구조가 깊은 인공신경망도 수렴이 잘 되도록 만들지만 이는 우리가 깊은 인공신경망을 필요로하는 이유를 무색하게 만든다. 때문에 데이터를 타겟에 매핑하는 간단한 매핑함수를 직접 구하기 어렵게 된다. 이는 왜 레이어의 수가 적어졌을 때 PreAct ResNet이 ResNet보다 낮은 성능을 보이는지 보여준다.
또한 masked modeling을 사용하여 변형모델이 중요한 돌파구를 찾을 수 있도록 했다. 아래 방정식과 같이 근사방식을 사용하여 의 역변환 를 찾을수 있도록 하여 변형된 피쳐가 공간적 특징을 이용하여 충분한 정보를 얻을 수 있도록 했다.
여기서 M은 dynamic binary mask다. 위 태스크를 해결하기 위해 일반적으로 사용되는 다른 방법은 디퓨전 모델이나 VAE이며 이들은 모두 역변환 함수를 찾기위한 함수를 가진다. 그러나, 이 방식을 경량화 모델에 적용하면 많은양의 원본 데이터에 대해 underparametered 되어 성능이 떨어지게 된다. 위와 같은 이유로 중요한 정보인 를 로 매핑하는 중요정보 는 같은 문제를 마주치게 될 것이다. 이런 이슈에 대해 본 연구에선 정보병목의 관점을 사용하여 살펴볼 것이다. 정보병목에 대한 공식은 아래와 같다.
일반적으로 는 의 작은 부분을 차지한다. 그러나 타겟 미션에선 중요하므로 비록 추론과정에서 정보손실의 크기가 중요하지 않더라도 I(Y,X)가 포함되는 한 훈련효과에 큰 영향을 미치게 된다. 경량화모델은 underparametered 상태이므로 추론단계에서 더 많은 중요정보를 잃기 쉽다. 위 분석에 기반하여 모델을 업데이트 하기 위해 신뢰가능한 미분값을 생성하면서 얕고 경량화된 신경망에 잘 맞는 방식을 제안한다.
Methodology
Programmable Gradient Information (PGI)
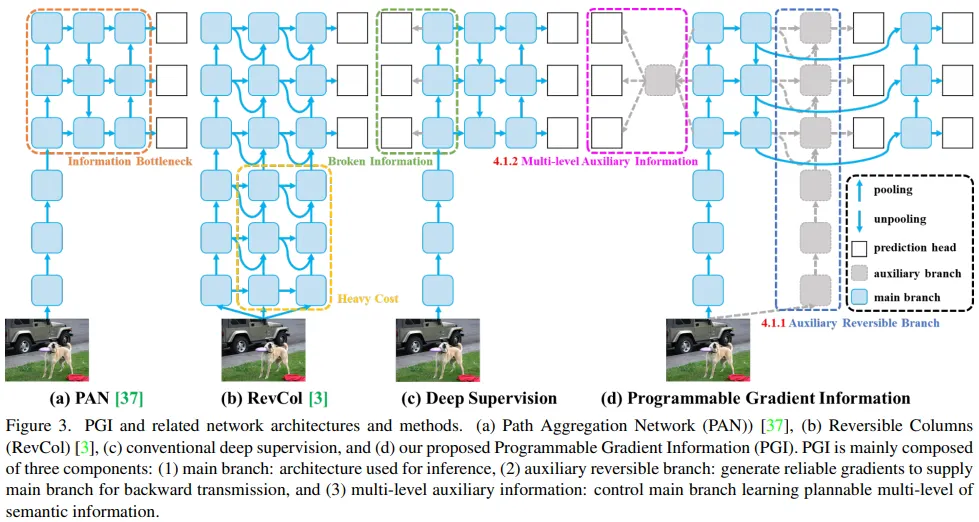
위 문제들을 해결하기 위해 위 그림과 같은 PGI라는 새로운 보조 감독학습 방법을 제안한다. PGI는 주로 3가지 컴포넌트를 포함하는데 1. main branch, 2. auxiliary reversible branch, 3. multi-level auxiliary information으로 구성된다. 3번그림의 d에서 main branch만 사용하는 PGI의 추론 과정을 확인할 수 있으며 어떤 추가적인 추론 비용이 필요하지 않음을 볼 수 있다. 다른 두 개의 컴포넌트는 딥러닝 메소드에서 중요한 이슈들을 해결하거나 완화하는데 사용된다. 이들중에 auxiliary reversible branch는 깊은 신경망 때문에 생기는 문제를 해결해준다. 깊은 신경망은 정보병목을 만들어 손실함수가 신뢰있는 미분값을 추정하지 못하게한다. 여러 레벨의 보조정보는 특히 경량모델 또는 아키텍쳐의 여러 예측 브랜치 등의 깊은 신경망으로 부터 나오는 수렴문제를 해결한다.
Auxiliary Reversible Branch
PGI에서 신뢰있는 미분값과 네트워크 파라미터 업데이트를 위해 auxiliary reversible branch를 제안했다. 데이터를 타겟에 매핑하는 정보를 제공하기 위해 손실함수는 가이드를 제공하고 타겟과 관련이 적은 완성도가 낮은 피드포워드 피쳐로 부터 생기는 잘못된 일치값에 대한 가능성을 회피하도록 한다. 본 연구에선 reversible architecture를 소개함으로써 완전한 정보를 유지하는 방식을 제안하였으나 reversible 구조에 main branch를 추가하는건 추론비용을 많이 사용하게 된다. 본 연구는 그림 3의 구조를 분석했고 깊은층에서 얕은 층으로 추가연결하는 부분이 추가되면 추론시간은 대략 20% 증가함을 알 수 있었다. 노란박스와 같이 입력데이터를 네트워크의 고해상도의 연산네트워크에 반복적으로 추가할 경우 2배의 시간이 걸렸다.
본 연구의 목표는 reversible 구조가 신뢰도 있는 미분값을 가짐에 있기 때문에 추론단계에서 reversible 한것은 꼭 필요한 조건이다. 이러한 관점에서 본 연구는 reversible branch를 깊은 감독 브랜치의 확장으로 생각하여 auxiliary reversible branch를 그림 3과 같이 설계하였다. main branch의 깊은 피쳐는 정보병목으로 인해 중요한 정보들을 잃기 때문에 auxiliary reversible branch로 부터 중요한 정보들을 가져올 수 있다. 이런 미분정보들은 파라미터의 학습이 정확하고 중요한 정보를 추출할 수 있게 돕고 위 작업들은 main branch가 타겟 태스트에 더 효율적으로 피쳐를 얻을 수 있도록 한다. 게다가, reversible 구조는 복잡한 태스크는 깊은 네트워크에서 변환을 요구받기 때문에 일반적인 네트워크보다 얕은 네트워크에서 성능이 더 떨어진다. 본 연구에서 제안하는 방식은 main branch가 완전한 원본 정보를 얻게 강제하진 않지만 auxiliary supervision 매커니즘을 통해 더 좋은 미분값을 생성하여 업데이트 하게 해준다. 이러한 설계는 얕은 네트워크에서도 적용될 수 있는 장점이 있다.
마지막으로ㅛ auxiliary reversible branch는 추론과정에서 삭제될 수 있으므로 원본 네트워크의 크기는 유지된다. 어떤 reversible 구조라도 PGI에서 auxiliary reversible branch의 역할을 할 수 있도록 했다.
Multi-level Auxiliary Information
본 섹션에선 어떻게 여러 레벨의 auxiliary information이 작동하는지 살펴본다. 그림 3을 보면 여러 예측 브랜치를 포함하는 깊은 감독 구조가 어떻게 생겼는지 확인할 수 있다. 객체인식을 위해 feature pyramids는 다른 크기의 객체를 탐지하는 등 다른 태스크를 이행하기 위해 사용된다. 그러므로 깊은 감독 프랜치에 연결 후 얕은 feature들은 작은 객체를 탐지하기 위해 요구되는 피쳐 학습을 가이드하게 되고 이 때 시스템은 다른 크기의 객체들을 배경으로 간주한다. 그러나 이는 깊은 feature pyramid가 타겟 객체를 예측하는데 필요한 정보를 잃게 한다. 본 연구에선 각 feature pyramid는 모든 타겟 객체에 대한 정보를 받아야 이후 main branch가 다양한 타겟 예측을 학습하기 위한 완전한 정보를 얻을 수 있다고 주장한다.
멀티 레벨 auxiliary information은 그림 3과 같이 auxiliary supervision의 계층 레이어 feature pyramid와 main branch사이에 사이에 병합 네트워크를 삽입하고 이를 다른 예측 헤더로 부터 반환된 미분값을 결합하는 식으로 구성하는것이다. 멀티레벨 auxiliary information은 모든 타겟 객체를 포함하는 미분 정보를 결합하고 이를 main branch에 전달하여 파라미터를 업데이트한다. 이 때, main branch의 feature pyramid 계층구조의 특징이 몇몇 특정한 객체의 정보에 억눌리지 않도록 한다. 그 결과 위 방법은 deep supervision에서 발생하는 정보 문제를 없애는데 도움을 주게 된다. 게다가 어떤 병합 네트워크도 멀티레벨 auxiliary information에서 사용될 수 있다. 그러므로 다른 크기의 네트워크 구조의 학습을 가이드하기 위한 의미론적 수준을 계획할 수 있게된다.
Generalized ELAN
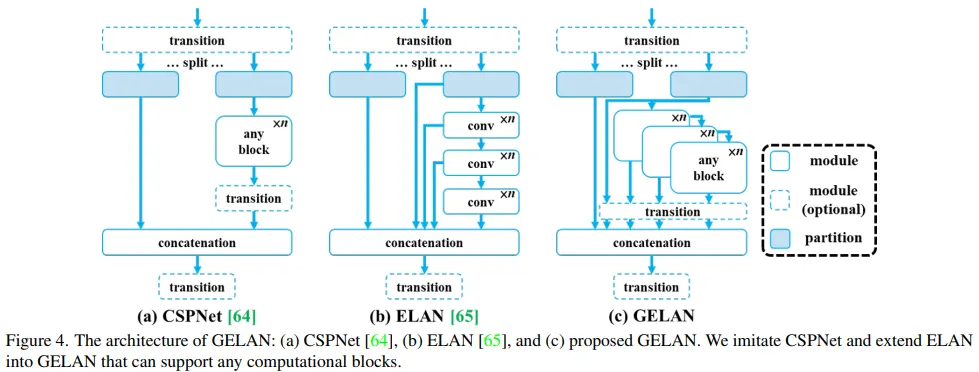
gradient path planning으로 설계한 CSPNet과 ELAN을 결합하여 가볍고 빠른속도와 높은 정확도를 가진 GELAN을 제안했다. 전체적인 구조는 위 그림 4와 같다. ELAN은 컨볼루션 레이어만을 쌓아서 만들었다.
Experiments
Experimental Setup
MSCOCO 데이터셋을 활용했으며 모든 실험은 YOLOv7 AF를 따랐다. 언급된 모든 모델은 train-from-scratch 전략을 사용하였고 전체 에포크는 500이다. 학습률 설정은 처음 3 에포크까진 linear warm-up을 사용하였고 이후 에포크는 모델의 크기에 따라 corresponding decay 방식을 사용했다. 마지막 15 에포크는 mosaic data augmentation을 껐다.
Implementation Details
YOLOv9는 YOLOv7와 Dynamic YOLOv7을 따랐다. 네트워크 구조 설계에서 ELAN을 연산 블록으로 RepDConv를 활용하는 CSPNet 블록을 사용하는 GELAN으로 대체하였다. 또한 다운샘플링 모듈을 간소화하고 anchor free 예측 헤더를 최적화 하였다. PGI의 auxiliary loss 부분을 위해 YOLOv7의 auxiliary 헤더 설정을 따랐다.