요약
현재 Transformer encoder 아키텍처를 활용한 연구들이 단일 이미지에 대한 3D human mesh recovery 분야에서 SOTA의 성능을 달성하고 있는 반면, large memory overhead와 slow inference speed 문제점을 가지고 있어 실무에 적용하기 어렵다. FastMETRO는 기존의 Transformer encoder 아키텍처의 문제점을 해결하는 동시에 SOTA에 견줄만한 성능을 달성하는 것을 목적한다. 이를 위해 Transformer encoder-decoder 아키텍처를 차용하여 기존 연구보다 적은 파라미터와 빠른 inference 속도를 나타내며, attention masking와 mesh upsampling 연산을 통해 빠른 convergence와 높은 정확도를 달성하였다.
Contribution
관련 연구
Human Mesh Reconstruction
FastMETRO
Method
입력 이미지에 대하여 3D human mesh를 recovery하는 transformer encoder-decoder 아키텍처
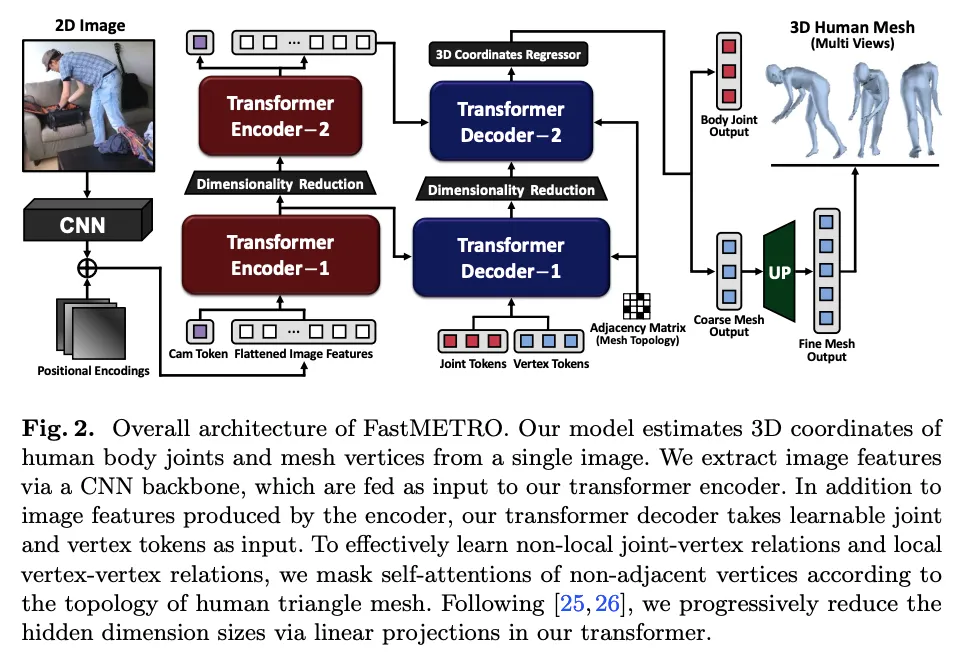
1. Feature Extractor
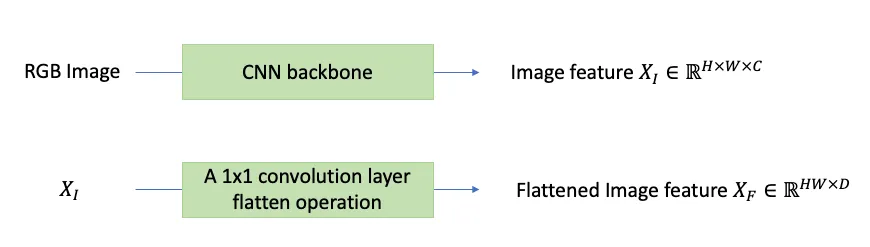
위와 같은 과정을 거친 후, spatial information을 유지하기 위한 positional encoding을 추가함
2. Transformer with Progressive Dimensionality Reduction
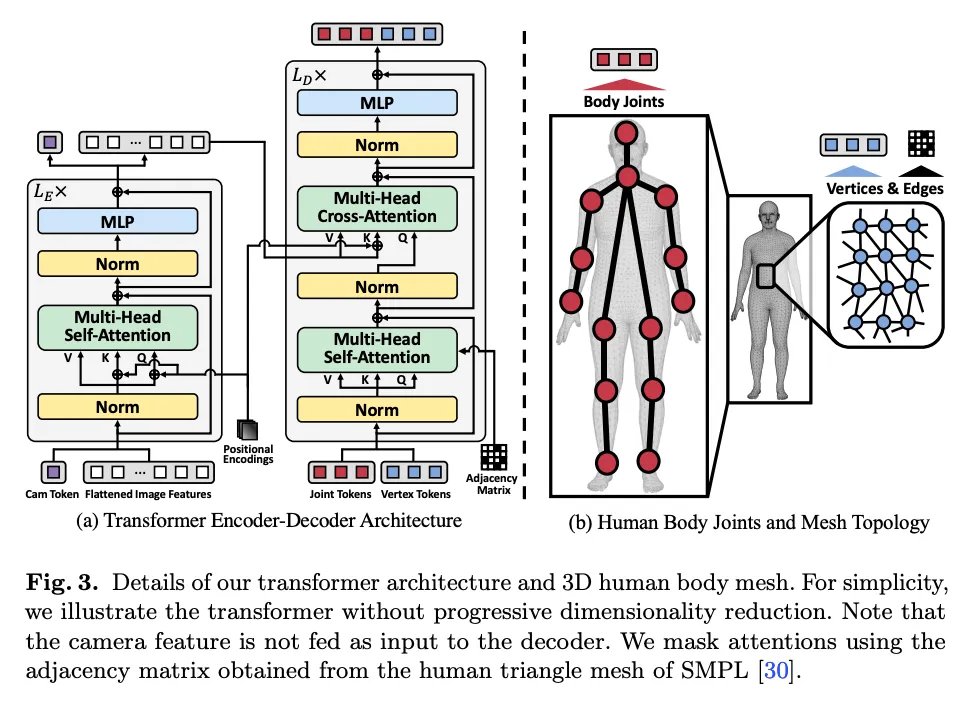
Transformer Encoder
Transformer Decoder
Attention Masking based on Mesh Topology
3. Regressor and Mesh Upsampling
3D Coordinates Regressor
Coarse-to-Fine Mesh Upsampling
4. Training FastMETRO
3D Vertex Regression Loss
3D Joint Regression Loss
2D Joint Projection Loss
Total Loss
Experiments
•