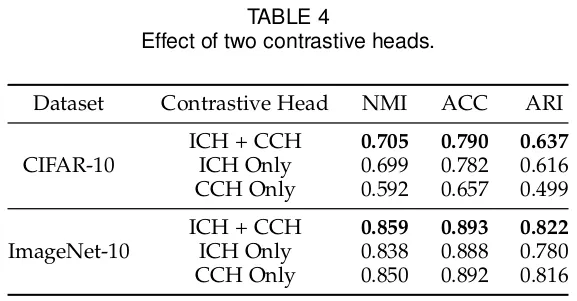
기존 연구들이 인스턴스 레벨과 클러스터 레벨의 representation을 한번에 하는것과 달리 본 연구는 이를 분리하여 ICH, CCH라는 두 개의 헤더로 분리하여 네트워크를 설계하였다. 각 데이터는 유사한것 끼리 붙고 다른것 끼리 떨어진다는 것만 적용한게 기존 방식이라면 본 방식은 각 데이터 뿐 만 아니라 전체 군집도 유사한 방식으로 적용한다는 것이 된다.
Introduction
•
훈련 가능한 feature matrix를 제안하였으며 이를 통해 instance representation과 cluster predict를 해결함
•
clustering에 특화된 Contrast Learning으로 instance-level 뿐 만 아니라 cluster-level까지 고려
•
one-stage이면서 end-to-end 방식으로 배치수준의 연산만 요구하므로 크 스케일의 온라인 시나리오에도 적용이 가능하다.
Related Work
Contrastive Learning
Contrastive learning은 representation learning에서 최근 SOTA를 달성하고 있는 비지도학습의 패러다임이다. contrastive learning의 기본 아이디어는 원본데이터를 positive pairs의 유사도는 최대화하고 negative pairs는 최소화 하는 feature space에 매핑하는것이다. 최근 이와 관련한 많은 연구들이 좋은 성능을 보이고 있으나 본 연구에서 제안하는 모델과는 몇가지 차이가 있다.
현재 존재하는 방식들은 instance level이나 본 연구는 instance level과 cluster-level을 모두 사용한다. 또한 기존 contrastive learning 방식들은 general representation을 학습하는데 집중하지만 본 연구는 클러스터링 태스크에 특화된 방식이다.
Deep Clustering
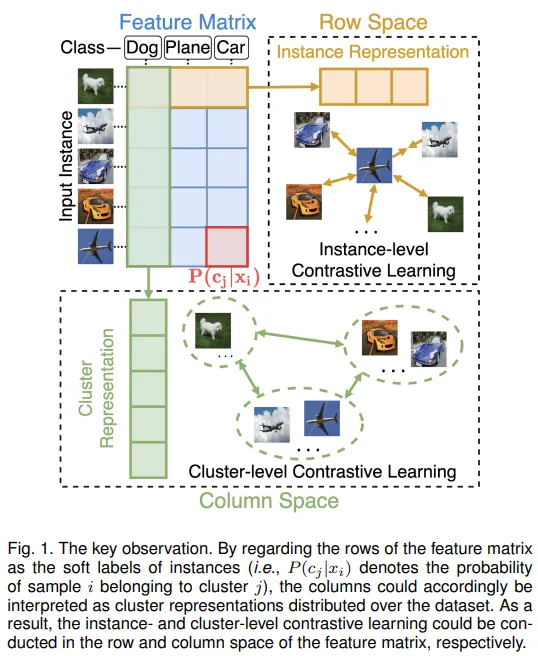
딥러닝의 강력한 representation 능력으로 딥러닝 기반의 모델들이 복잡한 데이터에도 좋은 성능을 보이고 있다. 그러나 이들은 설명하기 어려운 보조적인 over clustering 트릭에 크게 의존한다. 이와 달리 본 연구에선 라벨을 특별한 representation으로 다뤄 instance-level와 cluster-level로 행렬공간으로 구성하였다.
Method
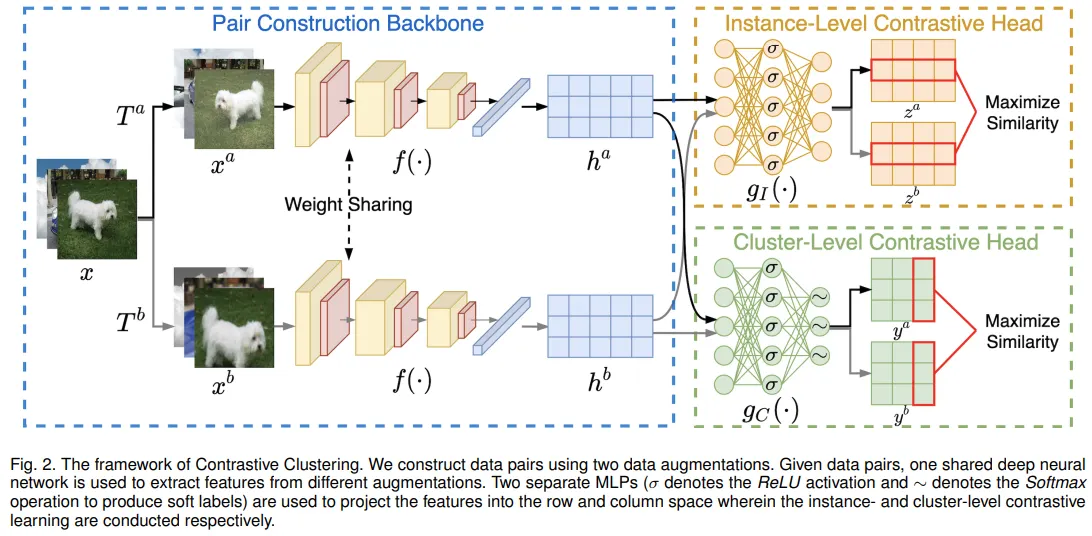
위 그림과 같이 본 연구의 모델은 세가지 컴포넌트로 구성되며 각각 pair construction backbone(PCB), instance-level contrastive head(ICH), cluster-level contrastive head(CCH)라 한다. 간단히, PCB는 데이터 어그멘테이션과 어그멘테이션된 샘플로 부터 추출한 피쳐 페어를 구성하며 이후 ICH와 CCH에 각각 피쳐매트릭스의 행렬 공간에 contrastive learning이 적용된다. 훈련 후에 CCH를 통해 쉽게 클러스터를 할당할 수 있다. 본 연구의 기본 아이디어는 dual contrastive learning이 피쳐매트릭스를 직접 구성할 수 있다는것이었으나 실험적으로 instance-level과 cluster-level의 contrastive lnearing을 독립된 서브스페이스에 분리함으로써 클러스터링 성능을 향상시켰음을 보였다. 본 현상의 원인은 분리전략이 ICH와 CCH의 표현능력을 향상시켰기 때문일 수 있다고 지적하였다.
Pair Construction Backbone(PCB)
이전 연구로 부터 영감을 받아 본 연구 또한 데이터쌍을 구성하기 위해 어그멘테이션을 활용하였다. 특히 데이터 인스턴스 가 주어졌을 때 두 확률론적 데이터 변환인 ,을 적용하여 와 를 얻었다. 이전 연구에선 좋은 성능을 보이기 위해 적절한 어그멘테이션 전략을 선택하였다. 본 연구에선 다섯가지 방법을 적용하였으며 각각 ResizedCrop, ColorJitter, Grayscale, HorizontalFlip, GaussianBlur에 해당한다.
Instance-level Contrastive Head(ICH)
Cluster-level Contrastive Head(CCH)
Objective Function
ICH, CCH 두 헤더에서 구한 손실값을 더해서 최종 손실함수는 아래와 같다.
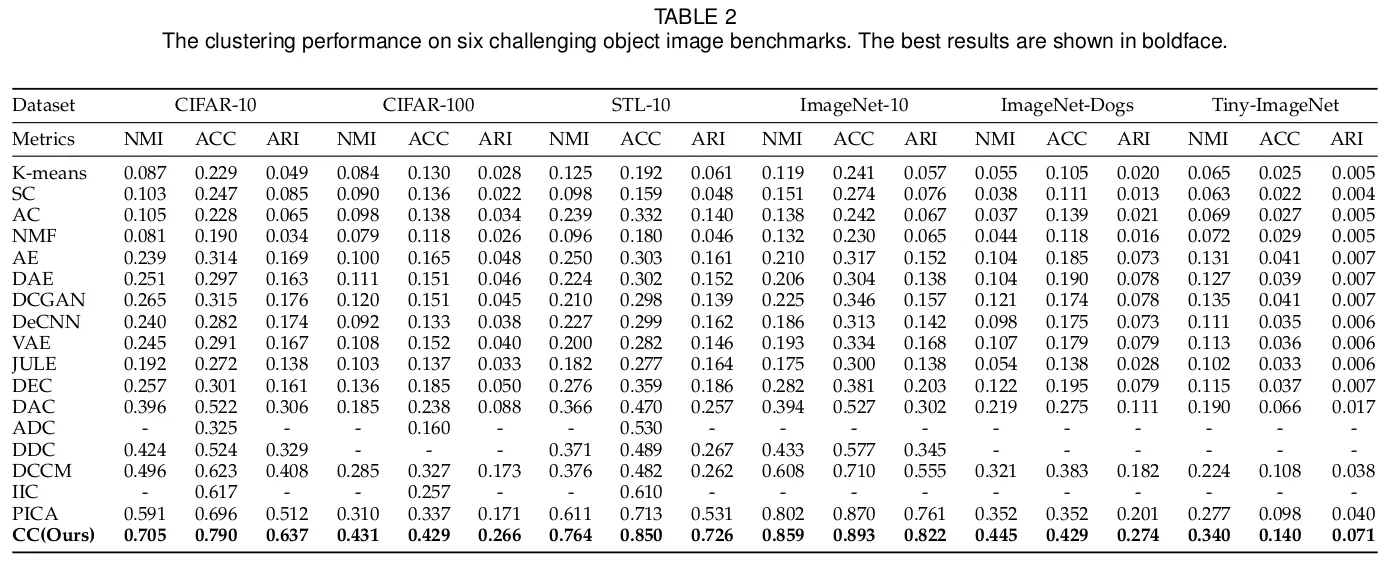
Experiments
Experimental Configurations
Datasets
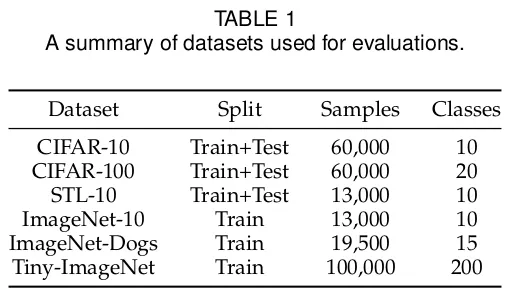
CIFAR-10, CIFAR-100, STL-10 데이터셋은 훈련셋과 테스트 셋 모두 활용했고 ImageNet-10, ImageNet-Dogs, Tiny-ImageNet은 훈련셋으로만 활용하였다. CIFAR-100은 GT값으로 100개 클래스가 아닌 슈퍼클래스 20개를 사용하였다. STL-10을 위해 해당 데이터셋의 100,000개의 라벨이 없는 샘플이 추가되어 ICH를 학습하기 위해 사용되었다.
Importance of Data Augmentation
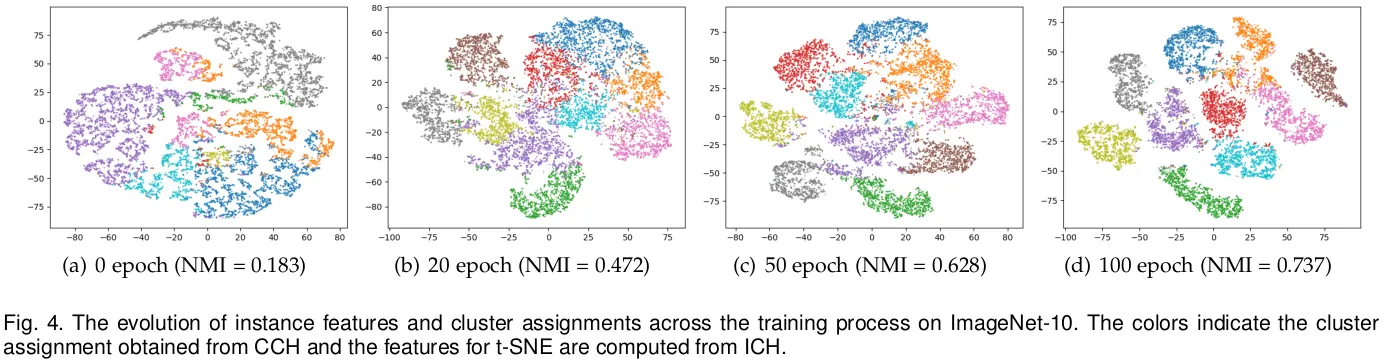
Effect of Contrastive Head
CCH의 유효성을 확인한다. CCH가 없는 경우 이를 kmeans로 대체하였다.